







Wie können Sie Elasticsearch nahtlos mit Ihrer Datenbank zusammenarbeiten lassen? Heute werden wir Ihnen helfen, diese Frage zu beantworten!
Was ist Elasticsearch?
Elasticsearch ist ein leistungsstolles Werkzeug für Suche und Analytik sowie eine flexible Datenlösung. Es basiert auf dem Lucene-Motor, der schnelle und effiziente Suchen in umfangreichen Datensätzen ermöglicht. Wenn Sie eine Webseite oder Anwendung haben und den Benutzern eine schnelle und bequeme Sucherfahrung bieten möchten, ist Elasticsearch eine ausgezeichnete Wahl.
Viele große Unternehmen, Firmen und Behörden vertrauen auf dieses Werkzeug. Die NASA verwendet Elasticsearch zur Verarbeitung und Analyse technischer Daten. IBM integriert es in ihre Cloud-Lösungen. Uber nutzt es zur Verarbeitung von geografischen Daten, während die New York Times es für sofortige Suchen in ihrer umfangreichen Artikel-Datenbank einsetzt.
Also, warum müssen wir Elasticsearch mit anderen Datenbanken integrieren und warum nicht Elasticsearch als primären Datenspeicher verwenden? In vielen Fällen kann Elasticsearch als Hauptlösung für die Speicherung dienen und schnellen Zugriff auf Informationen sowie effiziente Indizierung bieten. Es könnte jedoch nicht immer die ideale Lösung für bestimmte Aufgaben sein. Zum Beispiel ist Elasticsearch nicht für Transaktionen wie relationale Datenbanken oder das Speichern von Graphen wie Graphdatenbanken konzipiert. Durch die Kombination von Elasticsearch mit anderen Datenspeichersystemen können Sie die besten Eigenschaften jeder Technologie nutzen. Dadurch können Sie eine sofortige Suche mit Elasticsearch ermöglichen und gleichzeitig eine zuverlässige und effiziente Datenspeicherung in Ihrer Hauptdatenbank gewährleisten.
In diesem Artikel werden wir einige Möglichkeiten erkunden, Elasticsearch mit Datenbanken zu integrieren.
Wie können wir Elasticsearch mit Datenbanken integrieren?
Logstash
Logstash ist ein serverseitiges Werkzeug im ELK-Stack (Elasticsearch, Logstash, Kibana), das die Verarbeitung, Transformation und direkte Weiterleitung von Protokollen und Ereignissen aus verschiedenen Quellen an Elasticsearch ermöglicht. Sein Hauptzweck besteht darin, die Datenintegration zu vereinfachen.
Eine der essenziellen Funktionen von Logstash sind seine Plugins. Mit Eingabe-Plugins können Sie Daten aus verschiedenen Quellen extrahieren. Wenn Sie beispielsweise eine PostgreSQL-Datenbank haben und Daten von dort übertragen möchten, könnte eine Logstash-Konfiguration so aussehen:

Es gibt auch Plugins für NoSQL-Datenbanken wie MongoDB. Hier ist ein Beispiel, wie das konfiguriert werden kann:

Nachdem die Daten extrahiert wurden, beginnt Logstash mit der Verarbeitung mithilfe verschiedener Filter. Diese Filter können das Datenformat ändern, es anreichern und mehr. Um zum Beispiel das Datumsformat von „JJJJ-MM-TT“ in „TT/MM/JJJJ“ zu ändern, können Sie den folgenden Filter verwenden:

Sobald alle Transformationen abgeschlossen sind, sind die Daten bereit zur Weiterleitung. Um beispielsweise Daten an Elasticsearch zu senden, können Sie die folgende Konfiguration verwenden:

Was Logstash einzigartig macht, ist seine Flexibilität – Sie können es je nach Bedarf konfigurieren, dank der vielen verfügbaren Plugins. Zudem wird das Einrichten des Extraktions-, Verarbeitungs- und Datenweiterleitungsprozesses durch Konfigurationsdateien erleichtert. Es ist auch skalierbar und kann erhebliche Datenmengen verarbeiten, was es zu einer ausgezeichneten Wahl macht. Beachten Sie jedoch, dass Logstash ressourcenintensiv sein kann. Außerdem erfordert es möglicherweise Erfahrung, um es effektiv einzurichten und zu nutzen, obwohl es viele Fähigkeiten bietet.
Kafka
Apache Kafka ist ein System zur Verarbeitung von Streaming-Daten, das schnelle, zuverlässige verteilte Speicherung und Echtzeitübertragung von großen Datenmengen ermöglicht. In moderner IT-Infrastruktur ist Kafka oft eine wesentliche Komponente, die Millionen von Ereignissen pro Sekunde verarbeitet.
Um Daten erfolgreich aus Ihrer Datenbank in Elasticsearch mit Kafka zu integrieren, beginnen Sie damit, eine Verbindung zwischen Ihrer Datenbank und Apache Kafka herzustellen. Die Kafka-Community hat verschiedene Konnektoren und Plugins für verschiedene Arten von Datenbanken entwickelt. Diese Werkzeuge überwachen Änderungen in Ihrer Datenbank, oft mithilfe des Change Data Capture (CDC)-Mechanismus, und streamen diese Änderungen automatisch zu Kafka-Themen.
Angenommen, Sie verwenden PostgreSQL oder MongoDB-Datenbanken. Für PostgreSQL wird empfohlen, den Debezium-Konnektor zu verwenden. Dieser Konnektor verfolgt Änderungen in Ihrer Datenbank und leitet sie an das entsprechende Kafka-Thema weiter:
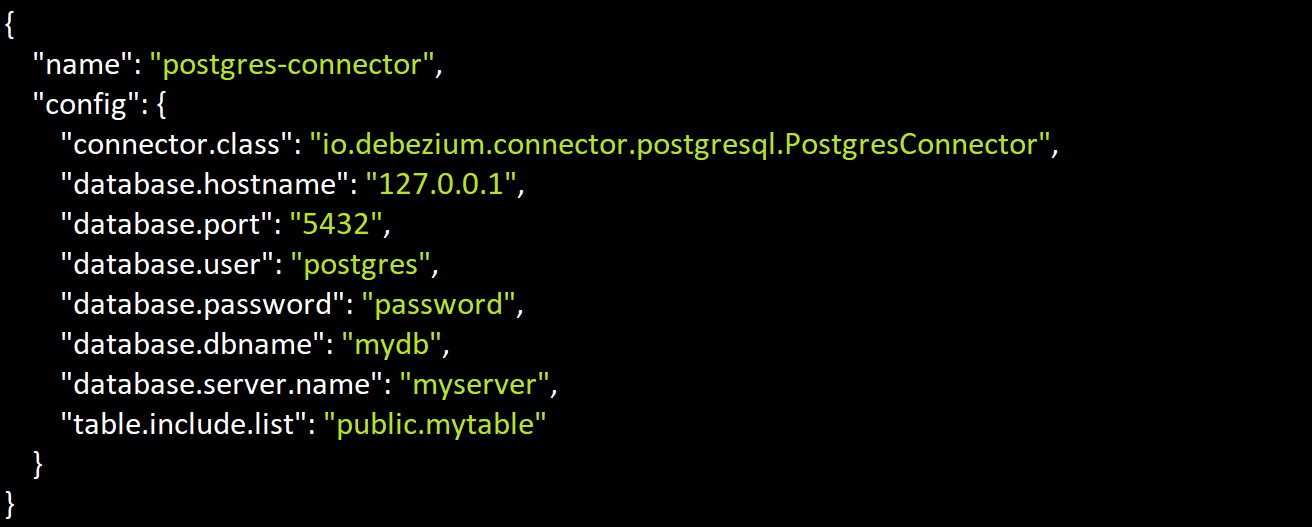
Für MongoDB können Sie den MongoSourceConnector verwenden:

Sobald die Daten in die Kafka-Themen gelangt sind, ist der nächste Schritt, sie für die weitere Integration in Elasticsearch vorzubereiten und zu optimieren. Werkzeuge wie Kafka Streams und Kafka Connect Transformations (Single Message Transforms) bieten die Möglichkeit einer effizienten Datenverarbeitung, um sie an die spezifischen Anforderungen von Elasticsearch anzupassen.
Schließlich erfolgt mit dem Kafka-Elasticsearch-Konnektor eine automatische Indexierung von Daten aus Kafka-Themen direkt in Elasticsearch, um deren Relevanz und Echtzeitsynchronisation zu gewährleisten.

Also, welche sind die Hauptvorteile der Integration von Apache Kafka und Elasticsearch? Die wichtigsten Vorteile sind Echtzeit-Datenverarbeitung und Robustheit. Kafka gewährleistet eine kontinuierliche Integration von Informationen, was insbesondere in Szenarien wichtig ist, in denen schnelle und zuverlässige Datenaktualisierungen entscheidend sind. Dank seiner verteilten Architektur und Datenreplikation garantiert Kafka auch einen kontinuierlichen Systembetrieb, selbst wenn einzelne Knoten ausfallen.
Es ist jedoch wichtig zu bedenken, dass die Implementierung und Unterstützung von Kafka ein tiefes Verständnis erfordern und herausfordernd sein können. Zudem können zusätzliche Infrastrukturaufwendungen die Kosten erhöhen. Dennoch wird Kafka in großen Streaming-Architekturen, in denen kontinuierliche Datenübertragung entscheidend ist, oft als bevorzugtes Werkzeug gewählt.
Auslöser und Zuhörer
Die direkte Integration mit Elasticsearch bietet eine effiziente Methode zur Datensynchronisation. Ohne Zwischenschritte oder zusätzliche Ebenen werden Änderungen aus Ihrer Datenbank schnell an Elasticsearch übermittelt, was die Datenverarbeitung und -analyse erleichtert.
In Fällen, in denen SQL-Datenbanken wie PostgreSQL verwendet werden, werden Triggermechanismen auf der Datenbankebene aktiv eingesetzt. Sie verfolgen alle Datenänderungen und generieren Benachrichtigungen. Diese Benachrichtigungen können von Zuhörern in Ihrer Anwendung abgefangen werden. Diese Zuhörer verarbeiten die Benachrichtigungen und senden die entsprechenden Aktualisierungen an Elasticsearch.

Für MongoDB gibt es eine Funktion namens „Change Streams“. Diese Funktionalität ermöglicht es Anwendungen, Datenänderungen in Echtzeit anzusehen und darauf zu reagieren. Change Streams bieten einen kontinuierlichen Zugriff auf den vollständigen Verlauf der Änderungen, einschließlich Informationen darüber, welche Daten geändert wurden und Kontextinformationen zu diesen Modifikationen.
Allerdings kann ein solcher Ansatz zusätzliche Belastungen auf Ihre Datenbank bringen. Darüber hinaus besteht bei vorübergehender Nichtverfügbarkeit von Elasticsearch das Risiko von Datenverlust, da kein Zwischenspeicher oder erneutes Sendesystem vorhanden ist. Daher hat die direkte Integration zwar bestimmte Vorteile, ist jedoch möglicherweise nicht für alle Fälle geeignet, insbesondere wenn Stabilität und Skalierbarkeit oberste Priorität haben.
Abschließend
Die Integration mit Elasticsearch kann eine anspruchsvolle Aufgabe sein, aber mit Wissen und den richtigen Werkzeugen können Sie ausgezeichnete Ergebnisse erzielen. Wie Sie aus diesem Artikel gelernt haben, gibt es mehrere Integrationsansätze, von denen jeder seine Vorzüge und Eigenheiten hat. Dies ist jedoch nicht die gesamte Liste potenzieller Methoden, und je nach Ihren spezifischen Anforderungen und Systemarchitektur können in der Praxis auch andere Strategien zum Einsatz kommen.
Wir hoffen, dass dieser Artikel als Ausgangspunkt in der Welt der Integration mit Elasticsearch dient. Zögern Sie nicht, zu experimentieren und stets nach neuen, optimaleren Lösungen zu suchen. Wir wünschen Ihnen viel Erfolg bei der Integration!
Schauen Sie sich die anderen Atikel von Elinext-Experten an.
