







Prädiktive Modellierung
Erinnerst du dich an das letzte Mal, als du eine Werbe-E-Mail mit einer sorgfältig zusammengestellten Liste von Artikeln erhalten hast, die tatsächlich deinen Interessen entsprachen? Das ist Predictive Analytics in Aktion.
Predictive Modeling, auch Prädiktive Analytik genannt, ist ein Prozess, der historische und Echtzeitdaten verwendet, um die Wahrscheinlichkeit von Ergebnissen und zukünftigen Ereignissen zu bestimmen. Neben den Daten ist das andere Stück des Puzzles der Predictive Analytics eine ausgefeilte Machine-Learning-Technologie, die für genaue Prognosen verantwortlich ist.
Angesichts der Fähigkeit, versteckte Muster aufzudecken und Chancen für Wachstum und Entwicklung zu entdecken, ist es kein Wunder, dass Predictive Modeling die Unterstützung einer breiten Palette von Organisationen gefunden hat. Im Jahr 2023 wurde der globale Predictive-Analytics-Markt auf 14,71 Milliarden US-Dollar geschätzt und soll von 18,02 Milliarden US-Dollar im Jahr 2024 auf 95,30 Milliarden US-Dollar im Jahr 2032 wachsen, was einer durchschnittlichen jährlichen Wachstumsrate von 23,1% im Prognosenzeitraum (2024-2032) entspricht.
Von E-Commerce über Finanzdienstleistungen bis hin zu Logistik- und Supply-Chain-Operationen investieren Organisationen verstärkt in Predictive Analytics, um Daten in aussagekräftige Erkenntnisse umzuwandeln und ihre Bilanzen zu verbessern. Amazon, der größte Online-Händler, plant, 700 Millionen US-Dollar zu investieren, um fast ein Drittel seiner Belegschaft für Datenanalyse-Rollen weiterzubilden.

Quelle: Grand View Research
Prädiktive Modelle bei der Arbeit
Mit dem explosionsartigen Anstieg von Big Data und Fortschritten in der maschinellen Datenverarbeitung sind predictive Modelle längst über das mathematische Gebiet hinausgewachsen. Heutzutage nutzen clevere Unternehmen die zahlreichen Vorteile von leistungsstarken predictive Analytics-Modellen, darunter:
- Echtzeit-Betrugserkennung. Verhaltensanalyse-Modelle können alle Netzwerkaktionen in Echtzeit analysieren, um verdächtige Muster sowie Zero-Day-Schwachstellen, Bedrohungen und Angriffsvektoren zu identifizieren. Diese Fähigkeiten sind besonders nützlich für die Finanzbranche. Mit Millionen von täglichen Transaktionen können Banken und Finanzinstitute datengesteuerte Analysen nutzen, um große Mengen an Finanzdaten zu verarbeiten und Kreditkartenbetrug effektiv zu erkennen.
- Verbessertes Risikomanagement. Versicherungsunternehmen und Insurtech-Unternehmen setzen predictive Analytics ein, um das Risiko von Zahlungsausfällen genau zu identifizieren. Mit ML-gestützten Kreditrisikobewertungsmodellen können eine Vielzahl relevanter Daten analysiert werden, um die Kreditwürdigkeit einer Person besser vorherzusagen und Underwriting-Verfahren zu optimieren.
- Personalisierung der nächsten Generation. Für Einzelhändler und E-Commerce-Unternehmen bieten datengesteuerte predictive Analytics-Modelle ein genaues Verständnis ihrer Kunden. Mit diesen Erkenntnissen können Marken Nachrichten und Angebote auf individueller Ebene besser anpassen, was zu einer besseren Kundenbindung und höherem Engagement führt.
- Vorhersagende Betreuung für gefährdete Patienten. Durch die Kombination von Daten aus verschiedenen Quellen wie elektronischen Patientenakten, medizinischen Wearables können Gesundheitsanalytik-Lösungen Gesundheitsdienstleistern helfen, Patienten zu identifizieren, die einem Risiko von Komplikationen ausgesetzt sind (wie Stürze bei älteren Patienten). Dies ermöglicht es medizinischen Fachkräften, sich rechtzeitig zu melden, bevor eine Komplikation auftritt, was Wiedereinweisungen verhindert und die Kosten für Rehabilitation reduziert.
Techniken der prädiktiven Analytik
-
Lineare Regression
Als Methode des überwachten Lernens gehört die lineare Regression zu den Verfahren, die versuchen, eine lineare Beziehung zwischen der Eingangsvariable und der Ausgangsvariable zu modellieren. Die grundlegende Idee hinter diesem häufigsten prädiktiven Modell ist es, vorherzusagen, wie unabhängige Variablen die abhängigen beeinflussen.
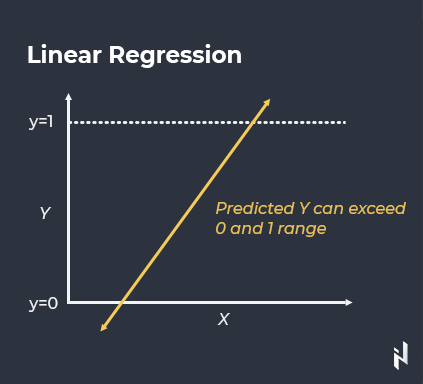
Quelle: Towards Data Science
-
Logistische Regression
Bei dieser Art der Vorhersagemodellierung ist keine lineare Beziehung zwischen der Ziel- und den abhängigen Variablen erforderlich. Einfach ausgedrückt beschäftigt sich die logistische Regression mit binären Daten, bei denen ein Ereignis entweder eintritt oder nicht, d.h. entweder eine Kreditkartentransaktion ist betrügerisch oder nicht, eine E-Mail Spam ist oder nicht, usw.
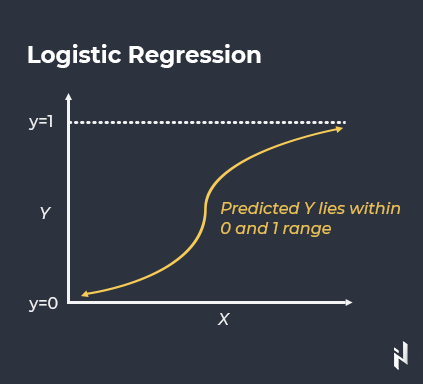
Quelle:Towards Data Science
-
Entscheidungsbäume
Als sehr effektiver Klassifikator sind Entscheidungsbäume auch leicht verständlich. Ein Entscheidungsbaum teilt die Stichprobe wiederholt basierend auf bestimmten Kriterien oder Fragen zur Stichprobe auf. Im Wesentlichen handelt es sich dabei um ein diagrammartiges Flussdiagramm, das Ihnen hilft, verschiedene Ergebnisse zu sehen und auszuwählen.
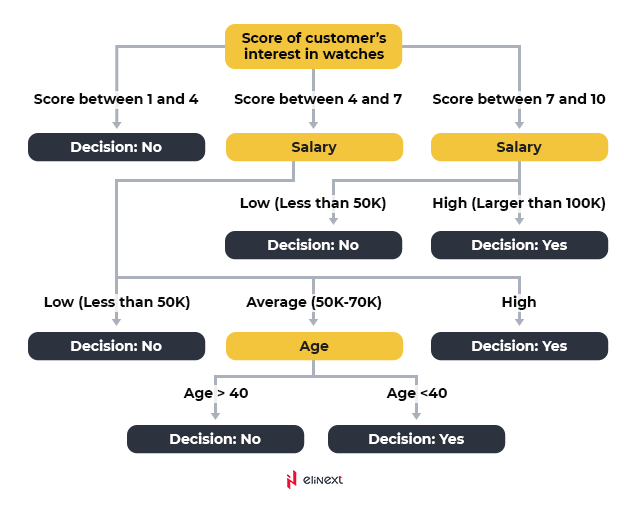
Quelle: Dummies
-
K-Means-Clustering
K-Means-Clustering ist eine Art von unüberwachtem maschinellem Lernen, das für Arten von Datensätzen ohne Beschriftung verwendet wird. Basierend auf den bereitgestellten Merkmalen weist der Algorithmus iterativ jedem Datenpunkt eine K-Gruppe zu, wobei K für die Anzahl der Gruppen steht und vordefiniert ist.
Diese Art von prädiktivem Modell ist vielseitig einsetzbar und kann zur Erstellung von Kundenprofilen, zur Entwicklung von Personas basierend auf Interessen, zur Gruppierung von Beständen nach Verkaufsaktivitäten und im Allgemeinen zur Erkennung bedeutungsvoller Veränderungen in Daten im Laufe der Zeit verwendet werden.
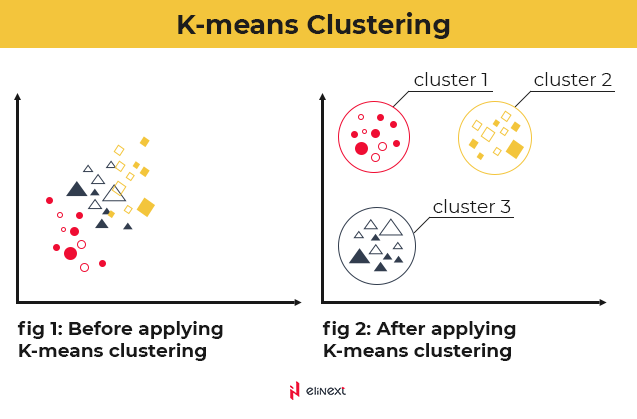
Quelle: Analytics Vidhya
-
Tiefe neuronale Netzwerke
Ein Teilgebiet des maschinellen Lernens sind neuronale Netzwerke, sehr komplexe Algorithmen, die versuchen, das menschliche Gehirn nachzuahmen. Ein tiefes neuronales Netzwerk (DNN) besteht aus mehreren Schichten künstlicher Neuronen, auch Perzeptronen genannt, die in zwischenlagiger Weise miteinander verbunden sind. Da sie in der Lage sind, komplexe Aufgaben zu lösen, werden DNNs in einer Vielzahl von Anwendungen eingesetzt – von selbstfahrenden Autos über Gesichtserkennung bis hin zur medizinischen Bildgebung.
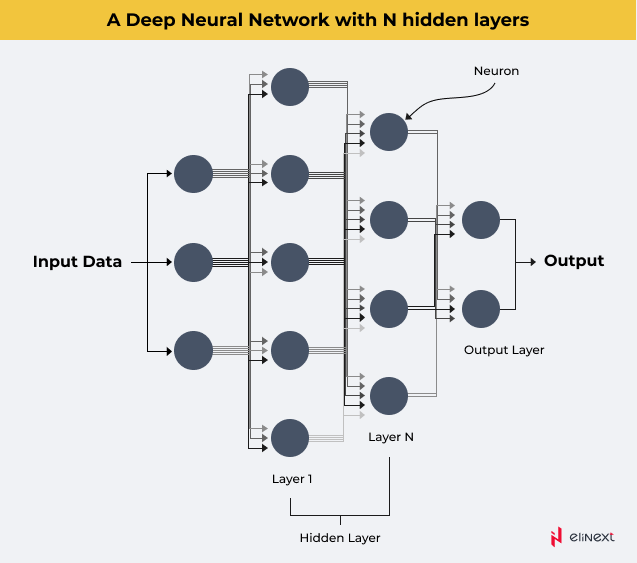
Quelle: Towards Data Science
Wir haben die wichtigsten Techniken der prädiktiven Modellierung besprochen, aber die Liste kann leicht weitergehen. Angesichts dieser Vielfalt ist es wichtig, das richtige Analysemodell von Anfang an auszuwählen, um genaue Prognosen zu erhalten und die individuellen Projektanforderungen zu erfüllen. Dafür gibt es zahlreiche Faktoren zu berücksichtigen, wie Zielvariablen, Datensatzgröße, verfügbare Rechenleistung usw.
Die Integration eines prädiktiven Modells in Ihre Lösung erfordert ausgereifte Softwareentwicklungsfähigkeiten sowie praktische Erfahrungen im maschinellen Lernen. Außerdem sollte jedes Team, das an einem prädiktiven Analyseprojekt arbeitet, Datenwissenschaftler einschließen, um datenbezogene Herausforderungen anzugehen.
Einschränkungen der prädiktiven Modellierung
- Unzureichende Datenqualität. Die Genauigkeit eines jeden prädiktiven Modells hängt von der Qualität der verwendeten Daten ab – ein Mangel an Daten kann zu einem Mangel im Modell führen. Wählen Sie geeignete Datenquellen aus und stellen Sie sicher, dass Ihre Daten vollständig, sauber und gepflegt sind.
- Algorithmische Voreingenommenheit. Unterrepräsentation oder unvollständige Trainingsdaten können die Waage kippen und die Entscheidungen des prädiktiven Modells zugunsten eines bestimmten Ergebnisses verzerren. Wenn diese Voreingenommenheiten nicht proaktiv angegangen werden, können sie zu unbeabsichtigter Diskriminierung führen und sogar potenziell schädliche Auswirkungen haben, wenn sie in einer Gesundheitslösung verwendet werden.
- Fehlen von massiven Trainingsdatensätzen. Um gut in der Klassifikation zu werden, benötigen prädiktive Modelle Tausende von Datensätzen. Für komplexere Aufgaben, die menschenähnliche Intelligenz erfordern, erfordern diese Modelle Millionen von Datenpunkten für das Training.
- Überanpassung/Unteranpassung des Modells. Überanpassung bezieht sich auf die Situation, wenn ein Modell zu eng mit dem Trainingsdatensatz ausgerichtet ist, indem es alle Details und Rauschen lernt, was es für neue Daten unbrauchbar macht. Andererseits bedeutet Unteranpassung, dass ein prädiktives Modell weder auf den Trainingsdaten gut funktioniert noch sich auf neue Daten verallgemeinern lässt.
Das Fazit
Von genaueren Betrugsvorhersagen über Echtzeit-Risikomanagement bis hin zu besser maßgeschneiderten Dienstleistungen und Angeboten ermöglichen prädiktive Analysemodelle Unternehmen, sich einen Wettbewerbsvorteil zu verschaffen und Wachstum zu fördern. Diese Modelle gibt es in verschiedenen Ausführungen und sollten basierend auf den individuellen Projektanforderungen ausgewählt werden. Daher kann es ratsam sein, mit einem Softwareentwicklungsunternehmen zusammenzuarbeiten, das Erfahrung im Aufbau von Datenanalyse-Lösungen hat und Sie sowohl bei der Auswahl des richtigen Ansatzes als auch bei der proaktiven Bewältigung von Herausforderungen beraten kann.
