







In der modernen Softwareentwicklung hat die Microservices-Architektur aufgrund ihrer Fähigkeit, komplexe Anwendungen in kleinere, verwaltbare Dienste zu zerlegen, immense Popularität gewonnen. Im Einklang mit diesem Trend ist die effektive Überwachung dieser Microservices von größter Bedeutung, um deren reibungslosen Betrieb und optimale Leistung zu gewährleisten. In diesem Artikel werden wir untersuchen, wie man eine Spring Boot-Anwendung mit Microservices-Architektur entwickelt und die Überwachung mit beliebten Tools wie Prometheus und Grafana implementiert.
Was ist Microservices-Überwachung?
Die Microservices-Architektur hat in der modernen Softwareentwicklung aufgrund ihrer Flexibilität, Skalierbarkeit und Widerstandsfähigkeit an Popularität gewonnen. Da Anwendungen jedoch immer verteilter und komplexer werden und mehrere Microservices miteinander interagieren, wird die Überwachung entscheidend, um deren reibungslosen Betrieb sicherzustellen. In diesem Artikel werden wir untersuchen, was Microservices-Überwachung ist, warum sie wichtig ist, und Beispiele für Überwachungsstrategien und -tools geben.
Verständnis der Microservices-Überwachung
Die Überwachung von Microservices umfasst den Prozess des Nachverfolgens und Überwachens des Verhaltens, der Leistung und der Gesundheit einzelner Microservices in einem verteilten System. Dazu gehört das Sammeln verschiedener Metriken, Logs und Traces von Microservices und deren Analyse, um Einblicke in deren Funktionsweise zu gewinnen. Die Hauptaufgaben der Microservices-Überwachung sind:
● Probleme erkennen: Die Überwachung hilft dabei, Probleme wie Leistungsengpässe, Fehler und Ausfälle in Microservices zu identifizieren und zu erkennen. Die frühzeitige Erkennung dieser Probleme ermöglicht ein rechtzeitiges Eingreifen und verhindert, dass sie sich zu ernsthafteren Problemen entwickeln.
● Leistungsoptimierung: Durch die Überwachung wichtiger Leistungsmetriken wie Antwortzeiten, Durchsatz und Ressourcenauslastung können Entwickler Optimierungsbereiche identifizieren und die Leistung von Microservices feinabstimmen, um die Gesamteffizienz des Systems zu verbessern.
● Sicherstellung der Verfügbarkeit: Die Überwachung stellt sicher, dass Microservices verfügbar und in der Lage sind, eingehende Anfragen zu bearbeiten. Sie hilft dabei, Ausfallzeiten, Ausfälle und Dienstunterbrechungen schnell zu erkennen, wodurch Probleme schnell behoben und Ausfallzeiten minimiert werden können.
● Skalierung und Kapazitätsplanung: Überwachungsmetriken in Bezug auf Ressourcennutzung, Verkehrsmuster und Microservice-Last ermöglichen eine effektive Skalierung und Kapazitätsplanung. Sie helfen dabei, zukünftige Ressourcenanforderungen vorherzusagen und Microservices horizontal oder vertikal nach Bedarf zu skalieren, um steigende Arbeitslasten zu bewältigen.
Beispiele für die Überwachung von Microservices
-
Metrikensammlung:
Die Metrikensammlung umfasst das Erfassen quantitativer Daten über verschiedene Aspekte des Verhaltens und der Leistung von Microservices. Beispiele für Metriken sind:
- Anfrageverzögerung: Die Zeit, die benötigt wird, um eingehende Anfragen zu verarbeiten.
- Fehlerrate: Der Prozentsatz der Anfragen, die zu Fehlern führen.
- Durchsatz: Die Anzahl der pro Zeiteinheit verarbeiteten Anfragen.
- CPU- und Speichernutzung: Ressourcennutzungsmetriken, die die Auslastung der Microservices anzeigen.
Tools wie Prometheus, Micrometer und StatsD werden häufig zum Sammeln von Metriken aus Microservices verwendet.
-
Log-Überwachung:
Logs bieten wertvolle Einblicke in die internen Abläufe von Microservices, einschließlich Debugging-Informationen, Fehlermeldungen und Anwendungsereignissen. Die Log-Überwachung umfasst das Aggregieren, Parsen und Analysieren von Log-Daten, um Anomalien, Trends und Muster zu erkennen. Tools wie der ELK-Stack (Elasticsearch, Logstash, Kibana), Fluentd und Splunk sind beliebt für die Log-Überwachung in Microservices-Umgebungen.
-
Verteiltes Tracing:
Verteiltes Tracing ermöglicht es, den Fluss von Anfragen zu verfolgen, die durch mehrere Microservices in einem verteilten System gehen. Dies hilft, die End-to-End-Verzögerung von Anfragen zu verstehen und Leistungsengpässe an verschiedenen Dienstkanten zu identifizieren. Tools wie Jaeger, Zipkin und OpenTelemetry bieten verteilte Tracing-Funktionen für Microservices-Architekturen.
-
Alarmierung und Benachrichtigung:
Alarmierungsmechanismen benachrichtigen Entwickler- und Betriebsteams über kritische Ereignisse, Anomalien oder Abweichungen vom erwarteten Verhalten in Microservices. Alarme können basierend auf vordefinierten Schwellenwerten oder Bedingungen für Metriken wie hohe Fehlerraten, erhöhte Latenz oder Dienstunverfügbarkeit konfiguriert werden. Tools wie Prometheus Alertmanager, Grafana und PagerDuty erleichtern die Alarmierung und Benachrichtigung in Microservices-Überwachungsumgebungen.
Die Überwachung von Microservices ist entscheidend, um die Zuverlässigkeit, Leistung und Verfügbarkeit von auf Microservices basierenden Anwendungen aufrechtzuerhalten. Durch die kontinuierliche Überwachung wichtiger Metriken, Logs und Traces können Organisationen den reibungslosen Betrieb ihrer Microservices sicherstellen und Probleme proaktiv lösen, bevor sie die Benutzer beeinträchtigen. Die Implementierung einer umfassenden Überwachungsstrategie mit geeigneten Tools und Techniken befähigt Entwickler, robuste und skalierbare Microservices-Architekturen zu erstellen, die den Anforderungen moderner Softwareanwendungen gerecht werden.
Verständnis der Microservices-Architektur
Die Microservices-Architektur umfasst das Aufteilen einer Anwendung in kleinere, unabhängige Dienste, die jeweils für einen spezifischen Funktionsbereich verantwortlich sind. Diese Dienste kommunizieren über APIs miteinander, was eine größere Flexibilität, Skalierbarkeit und Widerstandsfähigkeit der Anwendung ermöglicht.
Einrichtung einer Spring Boot-Anwendung
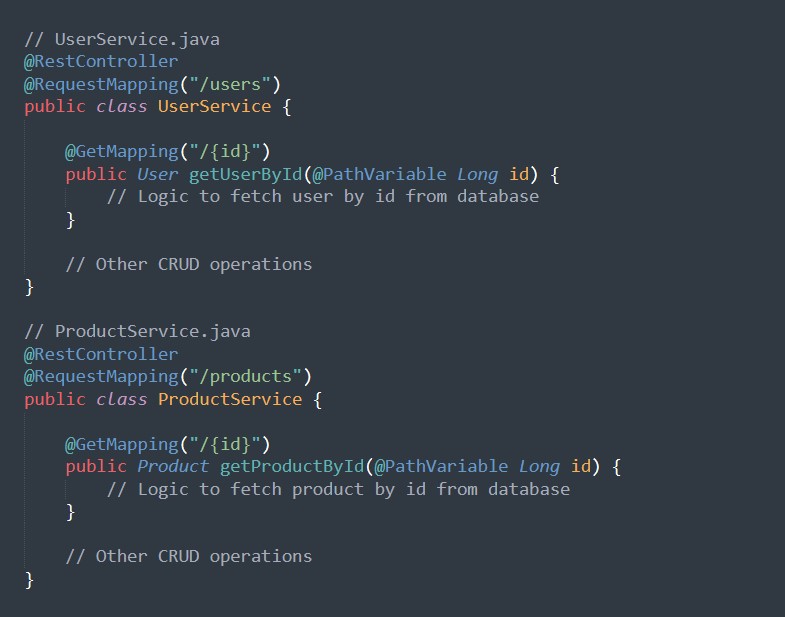
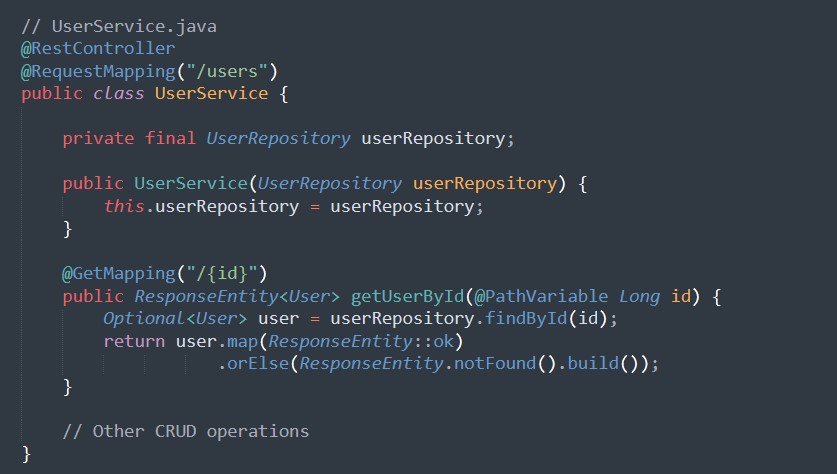
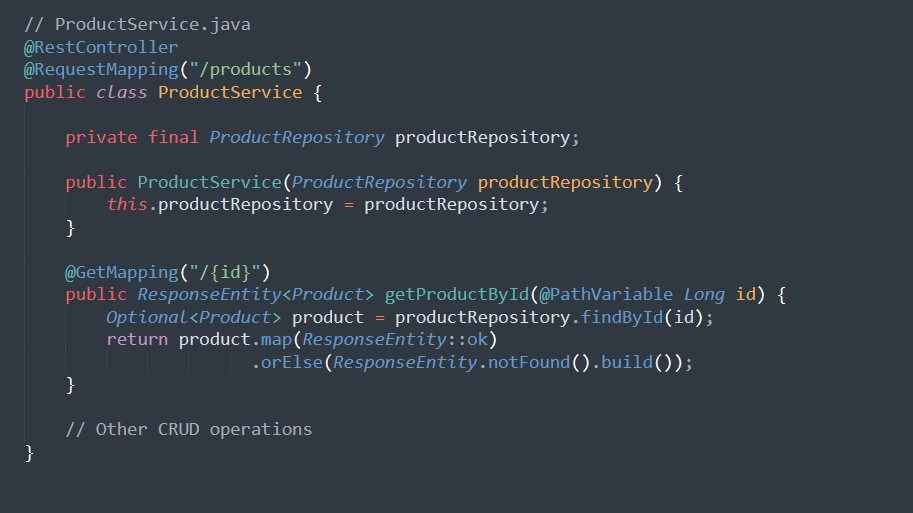
Um unsere Reise zu beginnen, richten wir eine einfache Spring Boot-Anwendung mit zwei Microservices ein: UserService und ProductService. Wir werden die Spring Boot Website- und Execution Engine-Starters verwenden, um RESTful APIs und Überwachungsendpunkte zu erstellen.
Beispielcode:
Überwachung mit Prometheus und Grafana implementieren
Da wir nun unsere Microservices eingerichtet haben, integrieren wir die Überwachung mit Prometheus zur Metrikensammlung und Grafana zur Visualisierung.
Beispielcode:
1.Fügen Sie Prometheus- und Actuator-Abhängigkeiten zu pom.xml hinzu:

2. Erstellen Sie eine Konfigurationsdatei prometheus.yml:
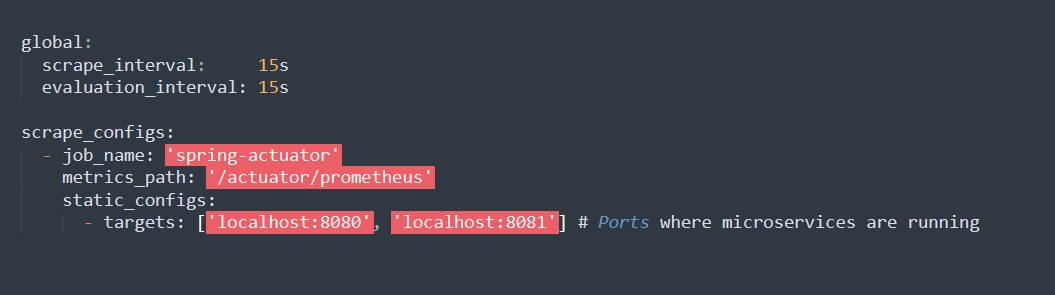
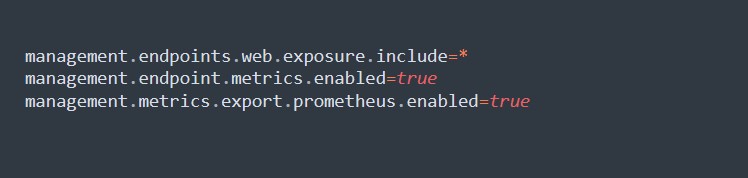
3. Konfigurieren Sie Prometheus in `application.properties`:
4. Führen Sie den Prometheus-Server mit Docker aus.

5. Richten Sie Grafana ein, um die von Prometheus gesammelten Metriken zu visualisieren.
Lassen Sie uns tiefer in die Nutzung von Prometheus und Grafana für umfassendes Monitoring eintauchen. Wir werden zusätzliche Metriken, benutzerdefinierte Dashboards und Benachrichtigungsmechanismen einführen, um sicherzustellen, dass wir das Beste aus unserer Monitoring-Konfiguration herausholen.
Verbesserung der Spring Boot Microservices
Schritt 1: Erweiterung der Microservices
Wir werden `UserService` und `ProductService` mit zusätzlichen Endpunkten und Metriken erweitern.
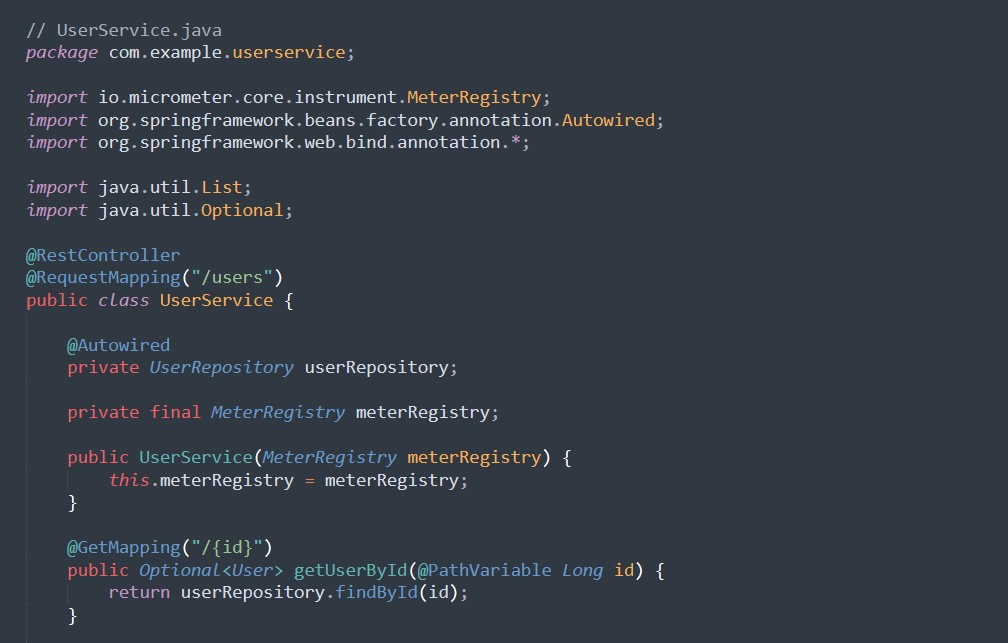
1.1 Erweiterte UserService
Fügen Sie Endpunkte hinzu, um alle Benutzer abzurufen und einen Benutzer zu löschen. Implementieren Sie außerdem eine benutzerdefinierte Metrik zur Verfolgung der Benutzererstellung.

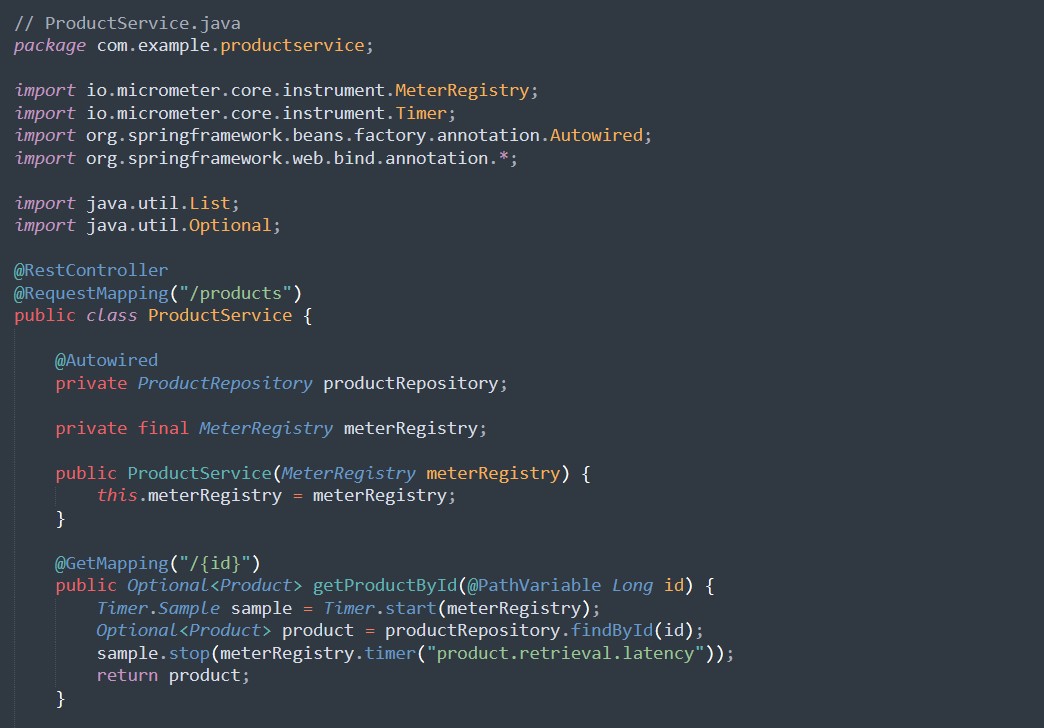
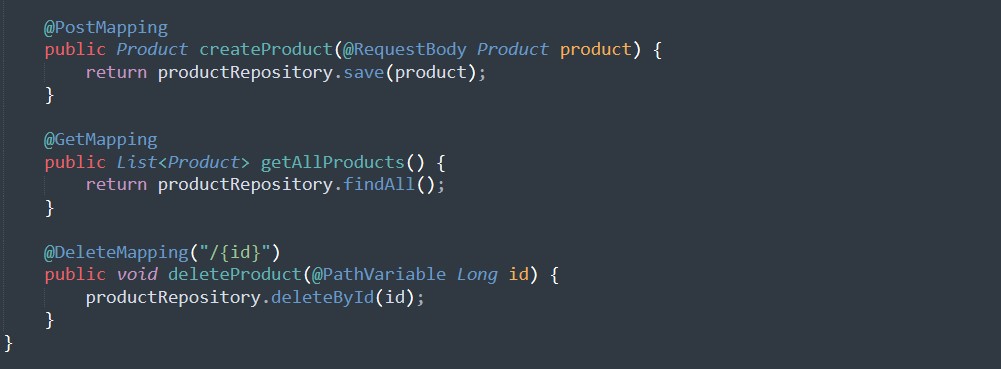
1.2 Erweiterte ProductService
Fügen Sie Endpunkte hinzu, um alle Produkte abzurufen und ein Produkt zu entfernen. Implementieren Sie auch eine benutzerdefinierte Metrik, um die Verzögerung beim Erhalt eines Produkts zu verfolgen.

 </h
</h
Schritt 2: Konfiguration für erweitertes Monitoring
2.1 Prometheus-Konfiguration
Aktualisieren Sie `prometheus.yml`, um erweitertes Metriken-Scraping einzuschließen.
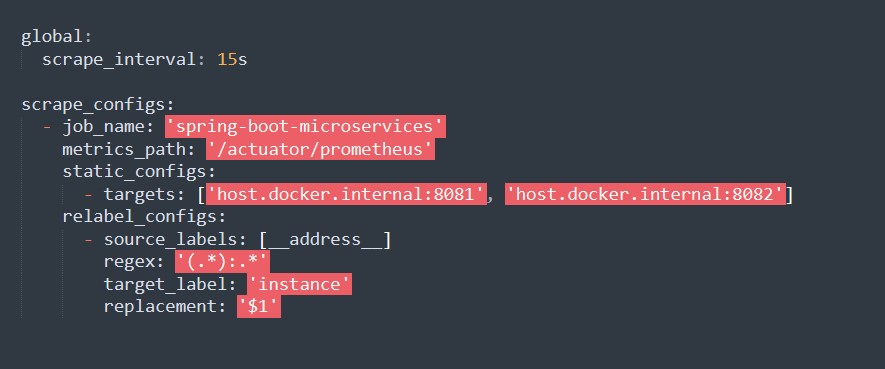
2.2 Grafana-Dashboards
Erstellen Sie benutzerdefinierte Grafana-Dashboards, um die gesammelten Metriken zu visualisieren. Hier sind einige Beispiele für nützliche Panels:
1. Anzahl der Benutzer:
- Visualisieren Sie die Gesamtzahl der erstellten Benutzer im Laufe der Zeit.
- Prometheus-Abfrage: `sum(increase(user_creation_count[1m]))`
2. Verzögerung beim Empfang von Produkten:
- Zeigen Sie die Latenzverteilung für den Produktabruf an.
- Prometheus-Abfrage: `histogram_quantile(0.95, sum(rate(product_retrieval_latency_bucket[5m])) by (le))`
3. CPU- und Speicherauslastung:
- Zeigen Sie die CPU- und Speicherauslastung für jeden Microservice an.
- Prometheus-Abfragen: `rate(process_cpu_seconds_total[1m])` und `process_resident_memory_bytes`
4. Fehlerquoten:
- Verfolgen Sie die Fehlerquote jedes Microservices.
- Prometheus-Abfrage: `rate(http_server_requests_seconds_count{status!~“2..“}[1m])`
Schritt 3: Einrichten von Benachrichtigungen
Konfigurieren Sie Prometheus, um Benachrichtigungen basierend auf spezifischen Bedingungen zu senden. Hier ist ein Beispiel für die Konfiguration zur Benachrichtigung über hohe Fehlerquoten und Latenz.
3.1 Prometheus-Benachrichtigungsregeln
Erstellen Sie `alert.rules.yml`, um Benachrichtigungsregeln zu definieren.
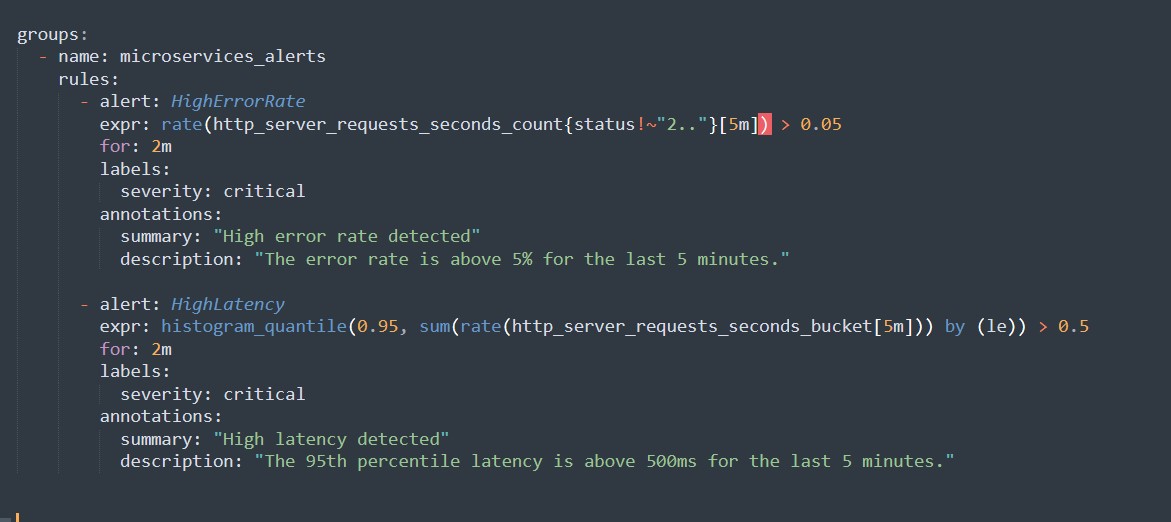
3.2 Konfiguration des Alertmanagers
Richten Sie den Alertmanager ein, um Benachrichtigungen zu verarbeiten. Erstellen Sie `alertmanager.yml`:

Schritt 4: Ausführen und Testen der Einrichtung
1. Starten Sie die Microservices:
- Stellen Sie sicher, dass sowohl `UserService` als auch `ProductService` ausgeführt werden.
2. Starten Sie Prometheus:
- `docker run -p 9090:9090 -v /path/to/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus`
3. Starten Sie Grafana:
- `docker run -d -p 3000:3000 grafana/grafana`
4. Starten Sie den Alertmanager:
- `docker run -d -p 9093:9093 -v /path/to/alertmanager.yml:/etc/alertmanager/alertmanager.yml prom/alertmanager`
5. Testen Sie die Panels und Benachrichtigungen:
- Greifen Sie auf Grafana unter `http://localhost:3000` zu, um die Dashboards anzuzeigen.
- Triggern Sie Benachrichtigungen, indem Sie hohe Fehlerquoten oder Latenz simulieren, und überprüfen Sie die Benachrichtigungen im Alertmanager.
Wir haben Prometheus konfiguriert, um detaillierte Metriken zu sammeln, und Grafana, um diese Metriken durch benutzerdefinierte Dashboards zu visualisieren. Darüber hinaus haben wir Benachrichtigungsmechanismen eingerichtet, um uns über kritische Probleme zu informieren. Diese umfassende Überwachungseinrichtung gewährleistet, dass wir die Leistung und Gesundheit unserer Microservices effektiv verfolgen, analysieren und darauf reagieren können, wodurch robuste und zuverlässige Anwendungen erhalten bleiben.
Vorteile der Microservices-Überwachung für Spring Boot-Anwendungen
Die Überwachung von Microservices in einer Spring Boot-Anwendung bietet zahlreiche Vorteile, die für die Entwicklung, Bereitstellung und Wartung moderner Softwaresysteme unerlässlich sind. Lassen Sie uns einige wichtige Vorteile genauer betrachten:
1.Früherkennung von Problemen
Die Überwachung von Microservices ermöglicht die frühzeitige Erkennung von Problemen wie Leistungsdegradierung, Fehlern und Engpässen innerhalb einzelner Dienste. Durch die kontinuierliche Überwachung von Metriken wie Antwortzeiten, Fehlerquoten und Ressourcennutzung können Entwickler potenzielle Probleme schnell identifizieren und lösen, bevor sie eskalieren. Dies gewährleistet optimale Leistung und Zuverlässigkeit.
2. Verbesserte Transparenz und Einblicke
Die Überwachung bietet Entwicklern detaillierte Informationen zum Verhalten und zur Leistung von Microservices. Durch das Sammeln und Analysieren von Metriken, Protokollen und Traces erhalten Entwickler Einblicke in das Verhalten jedes Dienstes, wie sie miteinander interagieren und wo potenzielle Probleme liegen. Diese Transparenz ermöglicht fundierte Entscheidungen, Fehlerbehebungen und Optimierungsbemühungen.
3. Verbesserte Leistungsoptimierung
Die Überwachung von Metriken im Zusammenhang mit CPU-Auslastung, Speicherverbrauch und Netzwerklatenz ermöglicht es Entwicklern, Leistungsengpässe und Optimierungsbereiche innerhalb von Microservices zu identifizieren. Durch die Lokalisierung von Ineffizienzen und Bereichen mit hoher Ressourcennutzung können Entwickler Code optimieren, Algorithmen verbessern und Konfigurationen feinabstimmen, um die Gesamtleistung und Effizienz zu steigern.
4. Proaktive Kapazitätsplanung
Die Überwachung von Microservices ermöglicht eine proaktive Kapazitätsplanung, indem sie Ressourcennutzungstrends, Verkehrsverläufe und Systemlast im Laufe der Zeit verfolgt. Durch die Analyse dieser Trends können Entwickler zukünftige Ressourcenanforderungen voraussehen und Microservices horizontal oder vertikal skalieren, um wachsende Arbeitslasten zu bewältigen. Dieser proaktive Ansatz zur Kapazitätsplanung trägt dazu bei, eine optimale Ressourcennutzung sicherzustellen und Leistungsdegradierungen aufgrund von Ressourcenbeschränkungen zu verhindern.
5. Fehlertoleranz und -isolierung
In einer Microservices-Architektur sind Dienste darauf ausgelegt, unabhängig und lose gekoppelt zu sein, sodass Fehler in einem Dienst isoliert und eingedämmt werden können, um zu verhindern, dass sie sich auf andere Dienste ausbreiten. Die Überwachung hilft dabei, Fehler in einzelnen Diensten zu identifizieren und zu isolieren, wodurch die Auswirkungen auf die Stabilität und Verfügbarkeit des gesamten Systems minimiert werden. Durch die schnelle Erkennung und Reaktion auf Fehler können Entwickler die Systemstabilität und -funktionalität aufrechterhalten, auch im Falle von partiellen Dienstausfällen.
6. Kontinuierliche Verbesserung und Iteration
Die Überwachung ermöglicht eine Kultur kontinuierlicher Verbesserung und Iteration, indem sie Echtzeit-Feedback zur Leistung und Gesundheit von Microservices bietet. Durch das Verfolgen von Schlüsselmetriken und die Analyse von Daten können Entwickler Bereiche für Verbesserungen identifizieren, neue Funktionen oder Konfigurationen ausprobieren und schnell iterieren, um bessere Benutzererfahrungen zu erzielen. Dieser iterative Entwicklungsansatz fördert Innovation, Flexibilität und Reaktionsfähigkeit auf sich ändernde Anforderungen.
Abschluss
In diesem Artikel haben wir die Entwicklung einer Spring Boot-Anwendung unter Verwendung der Microservices-Architektur erkundet und die Überwachung mithilfe von Prometheus und Grafana implementiert. Durch die Integration dieser Überwachungstools in unser Microservices-Ökosystem bieten wir eine bessere Sichtbarkeit der Leistung und Gesundheit unserer Dienste, was eine effektive Verwaltung und Fehlerbehebung ermöglicht.
Zusätzlich zu diesen Praktiken spielt mobile App-Entwicklung eine entscheidende Rolle bei der Verbesserung der Nutzerinteraktion und der Gewährleistung einer nahtlosen Leistung über verschiedene Plattformen hinweg.
Wenn Sie die Hilfe von Experten der Branche benötigen, wenden Sie sich an Elinext.
Lesen Sie weitere Artikel, die für Sie interessant sein können:
- Entwicklung einer Spring Boot Anwendung mit Elasticsearch-Integration
- Entwicklung einer Spring Boot Anwendung mit Websockets und Sockjs
- Entwicklung einer Spring Boot mit RabbitMQ
