







Vor einiger Zeit wurde mir die Aufgabe gestellt, einen Support-Chatbot zu erstellen, um Benutzeranfragen im Zusammenhang mit der Erstellung von virtuellen Maschinen (VM) und der Erlangung von VPN-Berechtigungen zu bearbeiten. Das Hauptziel bestand darin, Parameter zur Verarbeitung von Benutzeranfragen vorzubereiten. Der Chatbot sollte:
- Die Anfrage der Benutzer verstehen und die Gruppe der Anfrage bestimmen.
- Parameter für das Support-Team vorbereiten.
- Eine E-Mail an das Support-Team senden oder eine Aufgabe im Verwaltungsprogramm erstellen.
Ich weiß, es mag nicht die komplizierteste Aufgabe sein, aber wenn Sie möchten, dass Ihr Chatbot Anfragen in natürlicher Sprache versteht, wird diese Aufgabe anspruchsvoller.
Gibt es ein System, das bereits ein umfassendes Verständnis von Natural Language Processing (NLP) erreicht hat?
Die Antwort lautet ja, OpenAI-Modelle! Wenn wir über die GPT (Generative Pre-trained Transformer)-Modelle von OpenAI sprechen, durchlaufen sie Schulungen, um sowohl natürliche Sprache als auch Code zu verstehen. GPTs erzeugen textuelle Antworten auf Grundlage der bereitgestellten Eingaben, oft als ‚Prompts‘ bezeichnet.
Wir sollten im Hinterkopf behalten, dass ChatGPT ein großes Sprachmodell (Large Language Model, LLM) ist, eine Art von maschinellem Lernmodell. Ein Sprachmodell ist ein spezifisches künstliche Intelligenz-Modell, das Schulungen durchläuft, um menschliche Sprache zu verstehen und zu generieren.
Ein großes Sprachmodell (LLM) gehört zu einer bestimmten Kategorie von Sprachmodellen, die sich durch eine deutlich höhere Anzahl von Parametern im Vergleich zu traditionellen Modellen auszeichnet. LLMs werden auf umfangreichen Datensätzen trainiert, um das nächste Token in einem Satz unter Berücksichtigung des Kontexts vorherzusagen.
Nach dem Training kann ein LLM eine Feinabstimmung durchlaufen, um in verschiedenen Natural Language Processing (NLP)-Aufgaben herausragende Leistungen zu erzielen. Ein großes Sprachmodell verwendet tiefe neuronale Netzwerke, um Ausgaben zu erzeugen, indem es Muster aus den Schulungsdaten erkennt.
Es kann eine Vielzahl von Aufgaben im Bereich Natural Language Processing (NLP) durchführen, wie das Generieren und Klassifizieren von Text, das Beantworten von Fragen in einer Gesprächsweise und das Übersetzen von Text von einer Sprache in eine andere.
Beispiele für große Sprachmodelle (LLMs):
- GPT-3.5 / GPT-4 (Generative Pretrained Transformer) – von OpenAI.
- BERT (Bidirectional Encoder Representations from Transformers) – von Google.
- RoBERTa (Robustly Optimized BERT Approach) – von Facebook AI.
- Megatron-Turing – von NVIDIA.
Meine Wahl ist OpenAI
Die OpenAI-API ist äußerst vielseitig und für eine breite Palette von Aufgaben geeignet, die das Verstehen oder Erstellen von natürlicher Sprache und Code umfassen. Darüber hinaus ermöglicht die API die Generierung und Bearbeitung von Bildern sowie die Umwandlung von Sprache in Text. Sie bietet eine vielfältige Auswahl an Modellen, jedes mit unterschiedlichen Fähigkeiten und Preismöglichkeiten.
Es gibt einige GPT-Modelle, die von OpenAI entwickelt wurden.
- GPT-3.5-Modelle können sowohl natürliche Sprache als auch Code verstehen und generieren. Unter den GPT-3.5-Varianten zeichnet sich gpt-3.5-turbo als das leistungsfähigste und kosteneffizienteste Modell aus. Es ist speziell für Chat-Anwendungen durch die Chat Completions API feinabgestimmt, zeigt jedoch auch eine effektive Leistung bei herkömmlichen Abschlussaufgaben.
- GPT-4 verarbeitet derzeit Texteingaben und erzeugt entsprechende Textausgaben. Dieses Modell zeichnet sich durch die effektive Bewältigung komplexer Probleme aus und zeigt eine höhere Genauigkeit im Vergleich zu unseren vorherigen Modellen. Ähnlich wie gpt-3.5-turbo ist GPT-4 fein abgestimmt für chatbasierte Anwendungen und liefert eine ausgezeichnete Leistung bei typischen Abschlussaufgaben durch die Chat Completions API.
- GPT-Basismodelle besitzen die Fähigkeit, sowohl natürliche Sprache als auch Code zu verstehen und zu generieren, wenn auch ohne spezifische Anweisungen nach dem Training. Diese Modelle sind als Alternativen zu unseren ursprünglichen GPT-3-Basismodellen konzipiert und nutzen die herkömmliche Completions API.
- DALL·E ist ein KI-System, das in der Lage ist, realistische Bilder und Kunstwerke auf Grundlage einer natürlichen Sprachbeschreibung zu generieren.
- Embeddings sind numerische Darstellungen von Text, die die Bewertung der Korrelation zwischen zwei Textblöcken ermöglichen. Das neueste Embedding-Modell von OpenAI, text-embedding-ada-002, stellt einen Fortschritt der zweiten Generation dar und soll die 16 ursprünglichen Embedding-Modelle der ersten Generation ersetzen.
- Moderationsmodelle werden erstellt, um die Einhaltung der OpenAI-Nutzungsrichtlinien zu überprüfen. Diese Modelle bieten Klassifikationsfunktionen, um Inhalte in bestimmte Kategorien zu identifizieren, darunter Hass, bedrohliche Sprache, Selbstverletzung, sexueller Inhalt, Inhalte mit Minderjährigen, Gewalt und grafische Gewalt.
Sie können mit der API über HTTP-Anfragen aus jeder Programmiersprache interagieren, indem Sie entweder die offiziellen Python-Bindungen von OpenAI oder die offizielle Node.js-Bibliothek von OpenAI verwenden.
Die OpenAI-API verwendet API-Schlüssel zur Authentifizierung. Greifen Sie auf Ihren API-Schlüssel von der Seite mit den API-Schlüsseln zu, den Sie in Ihren Anfragen verwenden werden. Denken Sie daran, dass Ihr API-Schlüssel geheim ist!
Das GPT-3.5-Modell „gpt-3.5-turbo“ wurde ausgewählt, um einen Chatbot zu erstellen.
Nach umfangreichen Recherchen zu verschiedenen Modellen wurde festgestellt, dass „gpt-3.5-turbo“ das beste Gleichgewicht zwischen Ergebnissen und Kosten bietet.
Und hier sind wir beim ersten Schritt.
Erster Schritt
Schauen wir uns an, welche Möglichkeiten wir haben. Um die Modelle zu verwenden, muss ich eine Anfrage mit Nachrichten und einem API-Schlüssel senden. Danach sollte eine Antwort mit der Antwort eines Modells erfolgen.
Ich bin ein Python-Entwickler und habe die offizielle Python-Bibliothek von OpenAI ausgewählt, um die API zu verwenden, so seltsam es auch schien. Die Bibliothek verfügt über das Chat Completions API-Objekt und einen Aufruf, der dem folgenden Beispiel ähnelt:
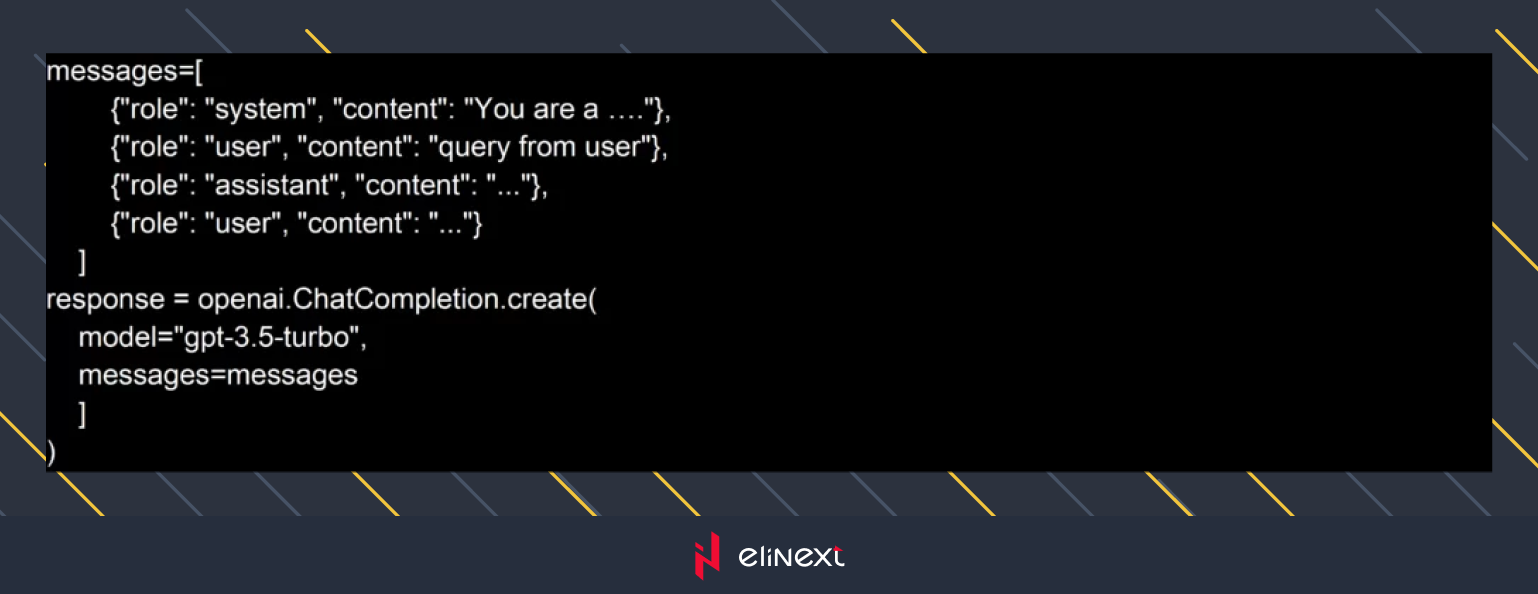
Die Antwort des GPT-Modells hat eine Struktur:

Der erste Schritt, den der Chatbot verstehen muss, besteht darin, die Gruppe der Anfrage zu bestimmen.
Um dieses Problem zu lösen, habe ich die Funktion mit dem Namen „Funktionsaufruf“ verwendet.
Um die Funktion „Funktionsaufruf“ zu verwenden, muss ich eine Liste mit Schemata von Funktionen erstellen. Das folgende Beispiel:
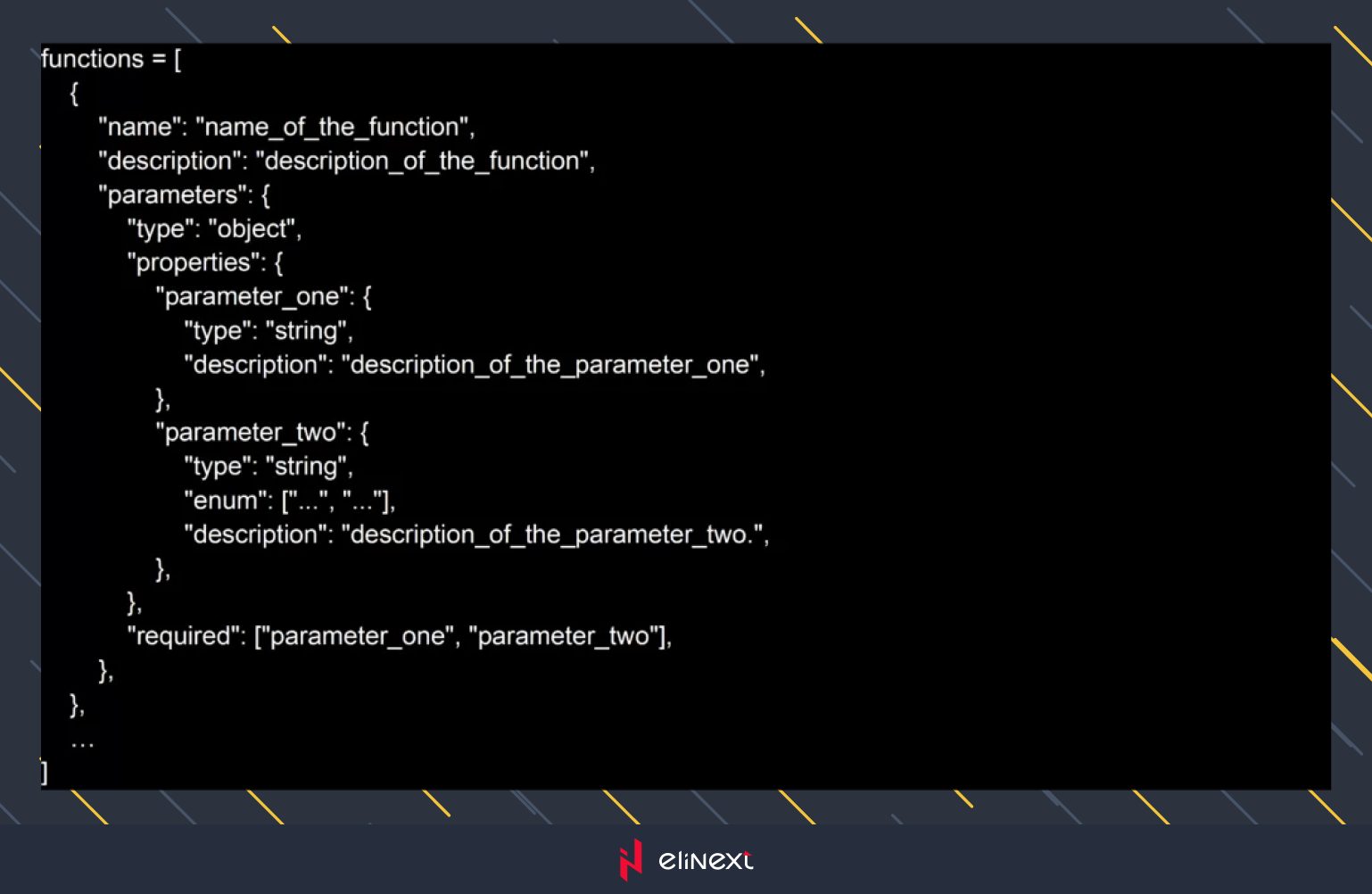
Nachdem ich die Liste der Funktionsstrukturen erstellt habe, habe ich sie in den Aufruf der Chat Completions API eingefügt.

Ich habe unterschiedliche Funktionen für verschiedene Gruppen erstellt, wie zum Beispiel eine für die Erstellung virtueller Maschinen (VM). Jede Funktion ist auf die spezifischen Bedürfnisse ihrer Gruppe zugeschnitten. Die Funktionen haben einzigartigen Inhalt für die jeweilige Gruppe.
Am Ende des ersten Schritts hatte ich die Benutzeranfrage und den Aufruf des Chatbots an das Modell mit dem vorbereiteten Kontext, der Benutzeranfrage und einer Liste von Funktionsspezifikationen. Das Modell wählt die Funktion aus und generiert ein JSON-Objekt mit den Argumenten, die benötigt werden, um diese Funktionen aufzurufen.
Die Funktionsspezifikation aus der offiziellen Dokumentation sieht beispielsweise so aus:
Das Modell wählt die Funktion mithilfe des vorbereiteten Kontexts aus und gibt eine Antwort im JSON-Format zurück.
Der Hauptalgorithmus für die Arbeit mit einem Modell sieht folgendermaßen aus:
- Rufen Sie das Modell auf, indem Sie die Benutzeranfrage und einen vordefinierten Satz von Funktionen über den Parameter ‚functions‘ übergeben.
- Das Modell kann eine Funktion auswählen, und wenn es das tut, wird der resultierende Inhalt ein JSON-Objekt sein, das einem spezifizierten benutzerdefinierten Schema folgt.
- Parsen Sie in Ihrem Code den String in JSON, und wenn die bereitgestellten Argumente vorhanden sind, fahren Sie fort, Ihre Funktion mit diesen Argumenten aufzurufen.
Um Funktionen zu überwachen, habe ich das Hauptmodul entwickelt. Das Hauptmodul des Chatbots enthält den gemeinsamen Inhalt dafür.
Das Hauptmodul des Chatbots wurde mit der Funktion entwickelt, verschiedene Funktionen für verschiedene Gruppen von Anfragen zu erhalten.
Zweiter Schritt
Der zweite Schritt besteht in der Vorbereitung der Parameter für das Support-Team.
Die Funktionsgruppe verfügt über einzigartigen Inhalt, um die Parameter aus einer Benutzeranfrage zu bestimmen. Funktionen können zusätzliche Fragen stellen und sogar eine zusätzliche Funktion für das GPT-Modell haben, um die Parameter korrekt vorzubereiten.
Darüber hinaus verwende ich zur Bestätigung der Parameter eine allgemeine Funktion. Die Funktion fordert den Benutzer zur Bestätigung auf. Da die Antwort des Modells probabilistisch ist, habe ich eine Funktion zur Bestätigung unter Verwendung klassischer Techniken erstellt.
Nach der Reaktion des Moduls hatte ich die JSON-Argumente mit den Parametern, die geparst und validiert werden mussten. Um die Parameter zu parsen und zu validieren, entschied ich mich für die Verwendung von „Pydantic“, das darin versiert ist.
Dritter Schritt
Und schließlich informiere das Support-Team, dass ein Problem vorliegt.
Um das Support-Team zu informieren, habe ich denselben Weg des Funktionsaufrufs verwendet.
Ich habe verschiedene Methoden verwendet, um mit dem Support-Team zu kommunizieren. Dafür habe ich verschiedene Funktionen erstellt und dem Benutzer die Wahl der Art und Weise gelassen, wie er das Support-Team informieren möchte. Aber in diesem Schritt habe ich alle Parameter für das Problem, und das GPT-Modell wählt einfach die Art und Weise, wie die Information übermittelt wird.
Fazit
Die Hauptidee für die Erstellung des Kundenservice-Chatbots bestand darin, natürliche Sprache in der Benutzeranfrage zu verwenden und den Inhalt in Nachrichten für das Modell aufzubauen.
Das verwendete Modell erzielte gute Ergebnisse bei der Auswahl von Funktionen und der Vorbereitung von Daten für ein Support-Team.
Dennoch sollte der Inhalt korrekt vorbereitet werden, und „Prompts“ sollten unter Verwendung von Empfehlungen des OpenAI-Teams geschrieben werden.
Nun, um einen eigenen KI-Chatbot zu erstellen, benötigte ich nur drei Schritte – alles umgesetzt im Rahmen der Python Entwicklung, wodurch die Integration, Anpassung und Automatisierung des Chatbots effizient realisiert werden konnte.
