







In der sich schnell entwickelnden Welt der künstlichen Intelligenz wird die Fähigkeit, Maschinen mit minimalen Daten zu trainieren, immer wichtiger. Hier kommen Few-Shot- und Zero-Shot-Learning-Techniken ins Spiel.
Diese Techniken ermöglichen es KI-Modellen, neue Objekte zu erkennen oder neue Aufgaben zu bewältigen, ohne dass umfangreiche Trainingsdaten vorhanden sind. Lassen Sie uns untersuchen, wie diese Methoden funktionieren, welche Bedeutung sie haben und wie sie die Zukunft der KI gestalten.
Was ist Few-Shot Learning?
Few-Shot Learning (FSL) ist ein leistungsstarkes maschinelles Lernparadigma, das darauf abzielt, Modelle zu entwickeln, die aus einer kleinen Menge an beschrifteten Daten generalisieren können. Dieser Ansatz ist besonders wertvoll, wenn keine großen annotierten Datensätze verfügbar sind, was in vielen realen Anwendungen wie der medizinischen Bildgebung, der Überwachung von Wildtieren und der personalisierten KI häufig der Fall ist.
Traditionelle maschinelle Lernmodelle erfordern in der Regel eine große Menge an beschrifteten Daten, um gute Leistungen zu erbringen. In vielen realen Szenarien ist es jedoch unpraktisch oder sogar unmöglich, solche großen Datensätze zu sammeln.
Few-Shot Learning versucht, diese Einschränkung zu überwinden, indem es auf Vorwissen aus verwandten Aufgaben zurückgreift, um auf neue Aufgaben mit minimalen Daten zu generalisieren. Stellen Sie sich zum Beispiel vor, ein KI-Modell soll verschiedene Vogelarten erkennen. Anstatt Tausende von beschrifteten Bildern für jede Art zu benötigen, könnte ein Few-Shot-Learning-Modell nur fünf oder zehn Bilder jeder Vogelart benötigen, um genaue Vorhersagen zu treffen.

Few-Shot-Learning-Beispiel
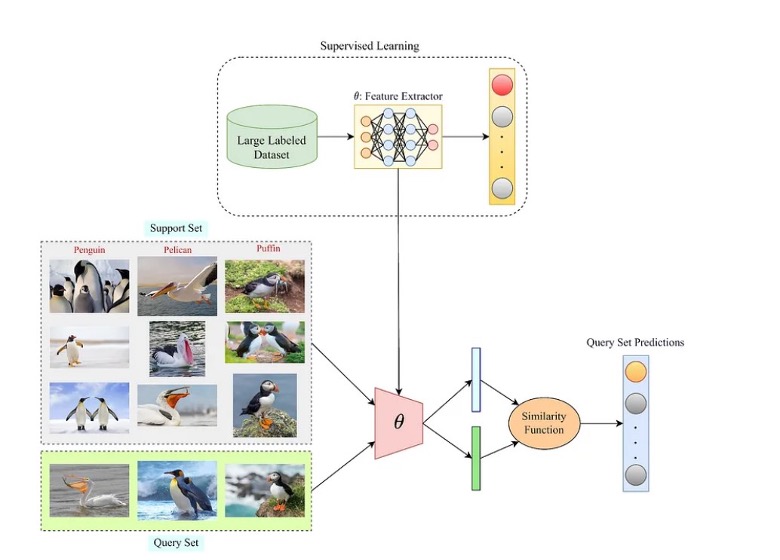
Quelle: Paperspace
Es gibt typischerweise drei Arten von Few-Shot Learning:
- One-Shot Learning: Das Modell wird darauf trainiert, Muster mit nur einem Beispiel pro Klasse zu erkennen.
- Few-Shot Learning: Das Modell wird mit einer kleinen Anzahl von Beispielen pro Klasse trainiert (z. B. 5-10).
- Zero-Shot Learning: Das Modell kann auf neue Klassen generalisieren, ohne während des Trainings Beispiele dieser Klassen gesehen zu haben.
Warum Few-Shot Learning?
Few-Shot Learning ist entscheidend für Szenarien, in denen Daten knapp, teuer oder zeitaufwändig zu sammeln sind. Einige Fakten, die die Bedeutung von FSL unterstreichen, sind:
- Datenknappheit: In vielen Bereichen, insbesondere in der Medizin, erfordert das Labeln von Daten Expertenwissen. Zum Beispiel kann es in der Radiologie Stunden oder Tage dauern, bis ein Radiologe medizinische Bilder annotiert.
- Effizienz: Few-Shot-Learning-Modelle können die Zeit und Ressourcen, die für die Bereitstellung eines maschinellen Lernsystems benötigt werden, erheblich reduzieren und machen KI zugänglich für kleine Unternehmen oder Forschungsgruppen mit begrenzten Daten.
- Anwendungen in der realen Welt: FSL wird in Anwendungen wie der Erkennung seltener Arten in der Tierwelt eingesetzt, wo möglicherweise nur wenige Bilder einer Art existieren, oder in der personalisierten KI, bei der sich Modelle an einzelne Nutzer auf der Grundlage begrenzter Interaktionsdaten anpassen müssen.
Wichtige Techniken im Few-Shot Learning
- Meta-Learning: Auch bekannt als „Lernen zu lernen“, beinhaltet Meta-Learning das Training eines Modells auf einer Vielzahl von Aufgaben, sodass es sich schnell an neue Aufgaben mit wenigen Beispielen anpassen kann.
- Prototypische Netzwerke: Bei diesem Ansatz lernt ein Modell, ein Prototyp (oder eine durchschnittliche Einbettung) für jede Klasse basierend auf den wenigen verfügbaren Beispielen zu erstellen. Wenn dem Modell eine neue Instanz präsentiert wird, vergleicht es diese mit den Prototypen und klassifiziert sie basierend auf der nächstgelegenen Übereinstimmung.
-
Siamese Netzwerke: Siamese Netzwerke werden verwendet, um Eingabepaaren zu vergleichen und festzustellen, ob sie zur gleichen Klasse gehören. Durch das Training an Beispielpaaren können diese Netzwerke lernen, Klassen mit minimalen Daten zu unterscheiden.
Few-Shot Learning implementieren
Um Few-Shot Learning zu implementieren, verwenden wir typischerweise Meta-Learning-Algorithmen wie Matching Networks, Prototype Networks oder Model-Agnostic Meta-Learning (MAML). Unten steht ein Python-Beispiel mit Prototypischen Netzwerken unter Verwendung des Torch-Frameworks.
Beispiel: Prototypische Netzwerke in PyTorch
Schritt 1: Erforderliche Bibliotheken importieren
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader from torchvision import transforms, datasets from torchvision.models import resnet18 import numpy as np
Schritt 2: Definieren des prototypischen Netzwerkmodells
class PrototypicalNetwork(nn.Module):
def __init__(self, embedding_dim):
super(PrototypicalNetwork, self).__init__()
self.encoder = resnet18(pretrained=True)
self.encoder.fc = nn.Linear(self.encoder.fc.in_features, embedding_dim)
def forward(self, x):
embeddings = self.encoder(x)
return embeddings
def prototypical_loss(prototypes, embeddings, labels, n_classes):
distances = torch.cdist(embeddings, prototypes)
labels = labels.view(-1, 1)
labels_onehot = torch.zeros(labels.size(0), n_classes).scatter_(1, labels, 1)
loss = nn.CrossEntropyLoss()(distances, labels_onehot.argmax(dim=1))
return loss
Schritt 3: Datenaufbereitung
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
train_dataset = datasets.ImageFolder(root='path_to_your_data', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
n_classes = len(train_dataset.classes)
embedding_dim = 128
Schritt 4: Training des Modells
model = PrototypicalNetwork(embedding_dim)
optimizer = optim.Adam(model.parameters(), lr=0.001)
n_epochs = 10
for epoch in range(n_epochs):
model.train()
for i, (images, labels) in enumerate(train_loader):
optimizer.zero_grad()
embeddings = model(images)
# Generate prototypes
prototypes = []
for class_idx in range(n_classes):
class_embeddings = embeddings[labels == class_idx]
class_prototype = class_embeddings.mean(dim=0)
prototypes.append(class_prototype)
prototypes = torch.stack(prototypes)
loss = prototypical_loss(prototypes, embeddings, labels, n_classes)
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}/{n_epochs}, Loss: {loss.item()}')
Schritt 5: Bewertung
Die Bewertung im Few-Shot Learning erfolgt häufig anhand von N-way K-shot Aufgaben, bei denen das Modell neue Beispiele korrekt klassifizieren muss, basierend auf wenigen beschrifteten Instanzen. Sie können das Modell bewerten, indem Sie solche Aufgaben erstellen und die Genauigkeit messen.
# Example evaluation with 5-way 1-shot classification
def evaluate(model, test_loader, n_classes, n_way=5, n_shot=1):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
embeddings = model(images)
prototypes = []
for class_idx in range(n_way):
class_embeddings = embeddings[labels == class_idx][:n_shot]
class_prototype = class_embeddings.mean(dim=0)
prototypes.append(class_prototype)
prototypes = torch.stack(prototypes)
distances = torch.cdist(embeddings, prototypes)
predictions = distances.argmin(dim=1)
correct += (predictions == labels).sum().item()
total += labels.size(0)
accuracy = correct / total
print(f'Accuracy: {accuracy * 100:.2f}%')
Few-Shot Learning in der Praxis
Eine bemerkenswerte Anwendung von FSL ist die Gesichtserkennung für Sicherheitssysteme. Traditionelle Gesichtserkennungssysteme erfordern große Datensätze mit beschrifteten Gesichtern, was für einzelne Benutzer oder kleine Organisationen unpraktisch sein kann. Mit FSL kann ein Modell nur mit wenigen Bildern des Gesichts einer Person trainiert werden und dennoch eine hohe Genauigkeit bei der Erkennung der Person unter verschiedenen Bedingungen erreichen.
Eine Studie von Snell et al. (2017) zeigte, dass Prototypische Netzwerke eine Genauigkeit von 49,42 % im mini-ImageNet-Datensatz nur mit 1-Shot-Learning erreichten, was die Effektivität von FSL in herausfordernden Umgebungen demonstriert.
Das Konzept des FSL wurde in der Industrie weit verbreitet angenommen, wobei Unternehmen wie Google und Facebook Modelle entwickeln, die FSL nutzen, um personalisierte Benutzererlebnisse zu verbessern.
Herausforderungen und zukünftige Richtungen
Trotz ihres Potenzials bringt Few-Shot Learning Herausforderungen mit sich. Dazu gehört die Schwierigkeit, sicherzustellen, dass Modelle gut auf völlig neue Aufgaben generalisieren, sowie die rechnerische Komplexität einiger Meta-Learning-Algorithmen. Darüber hinaus bleibt die Entwicklung robuster semantischer Repräsentationen, die die Eigenschaften ungesehener Klassen genau erfassen, eine anhaltende Herausforderung.
In Zukunft wird die Forschung in Bereichen wie selbstüberwachtem Lernen, Transferlernen und der Integration multimodaler Daten (z. B. die Kombination von Text und Bildern) wahrscheinlich die Fähigkeiten des Few-Shot und Zero-Shot Learning weiter voranbringen. Während sich diese Techniken weiter entwickeln, werden sie eine entscheidende Rolle dabei spielen, KI anpassungsfähiger, effizienter und zugänglicher in verschiedenen Branchen zu machen.
Fazit
Few-Shot Learning verändert die Art und Weise, wie wir maschinelles Lernen in datenarmen Umgebungen angehen. Durch den Einsatz von Modellen wie Prototypischen Netzwerken können wir Systeme schaffen, die effektiv aus minimalen Daten lernen und neue Möglichkeiten in Bereichen eröffnen, in denen die Datensammlung herausfordernd ist. Da Forschung und Technologie weiterhin fortschreiten, können wir erwarten, dass FSL eine entscheidende Rolle im breiteren KI-Umfeld spielt.
