







Multimodales Lernen, das die Integration mehrerer Datenmodalitäten wie Text und Bilder umfasst, ist ein schnell wachsendes Feld im maschinellen Lernen. Dieser Ansatz nutzt die komplementären Stärken verschiedener Datentypen, um die Leistung und Fähigkeiten von KI-Modellen zu verbessern.
Überblick über das Multimodale Lernen
Menschen nutzen ihre fünf Sinne – Sehen, Hören, Tasten, Schmecken und Riechen –, um unterschiedliche Arten von Informationen zu sammeln und zu integrieren. Diese Fähigkeit ermöglicht es uns, komplexe Situationen, wie etwa ein Gespräch, zu verstehen, indem wir sensorische Eingaben kombinieren.
KI versucht, diesen Prozess durch Multimodales Deep Learning nachzuahmen, indem Modelle dazu gebracht werden, verschiedene Datentypen zu verarbeiten und zu kombinieren, um ein umfassenderes Verständnis zu erreichen. Dieser Artikel behandelt, wie multimodale Fusion funktioniert, die Rolle multimodaler Datensätze und die Anwendungen dieser Technologien, und erklärt, wie KI-Modelle eine ganzheitlichere Sicht auf Informationen erreichen.
Multimodales Lernen kombiniert verschiedene Datentypen, um ein umfassenderes und nuancierteres Modell zu erstellen. Zum Beispiel kann die Kombination von Text- und Bilddaten Aufgaben wie Bildbeschreibung, visuelle Fragebeantwortung (VQA) und cross-modale Suche erheblich verbessern.
Schlüsselkonzepte
- Merkmalsextraktion: Extraktion von bedeutungsvollen Merkmalen aus sowohl Texten als auch Bildern.
- Modalitätsfusion: Kombination der Merkmale aus verschiedenen Modalitäten.
- Lernstrategie: Training des Modells auf den kombinierten Daten.
Wie funktioniert Multimodales Lernen?
Multimodale neuronale Netzwerke kombinieren typischerweise mehrere unimodale neuronale Netzwerke, die jeweils darauf spezialisiert sind, eine andere Art von Daten zu verarbeiten. Ein audiovisuelles Modell könnte beispielsweise ein Netzwerk für visuelle Daten und ein anderes für Audiodaten haben. Diese unimodalen Netzwerke verarbeiten ihre jeweiligen Eingaben getrennt durch einen Prozess, der als Kodierung bezeichnet wird. Nachdem jede Modalität kodiert wurde, werden die extrahierten Merkmale durch verschiedene Fusionstechniken kombiniert, die von einfacher Konkatenation bis hin zu komplexen Aufmerksamkeitsmechanismen reichen. Dieser Fusionsprozess ist entscheidend für die Leistung des Netzwerks.
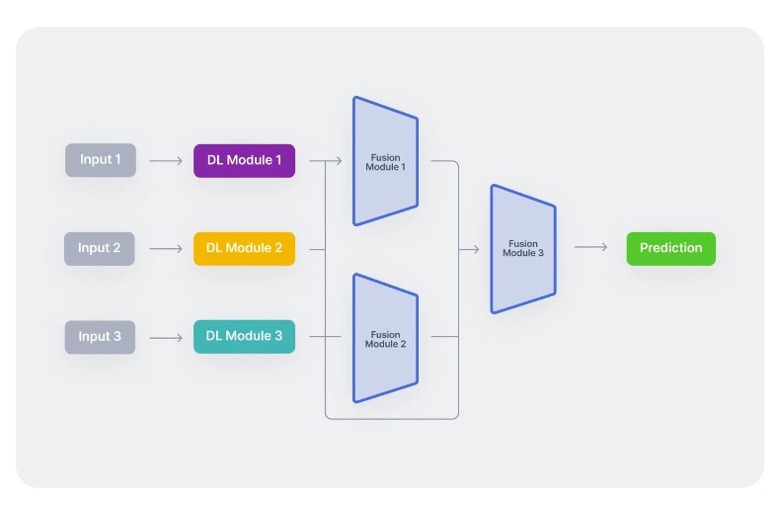
Im Wesentlichen bestehen multimodale Architekturen aus drei Hauptkomponenten:
Unimodale Encoder: Separate Netzwerke zur Kodierung jeder Eingabemodalität.
Fusionsnetzwerk: Ein System, das die Merkmale jeder Modalität nach der Kodierung kombiniert.
Klassifikator: Ein Netzwerk, das die kombinierten Daten verarbeitet, um endgültige Vorhersagen zu treffen.
Diese Komponenten werden häufig als das Kodierungsmodul, das Fusionsmodul und das Klassifikationsmodul bezeichnet.
In einem typischen multimodalen Workflow kodieren drei unimodale neuronale Netzwerke zunächst unabhängig voneinander verschiedene Eingabemodalitäten. Nach der Merkmalsextraktion kombiniert ein Fusionsmodul diese Modalitäten – oft werden sie paarweise zusammengeführt. Schließlich werden die integrierten Merkmale in ein Klassifikationsnetzwerk eingespeist, um den endgültigen Entscheidungsprozess durchzuführen.

Typischer multimodaler Arbeitsablauf
Anwendungen des Multimodalen Deep Learnings
Bildwiederherstellung
Die Bildwiederherstellung umfasst das Durchsuchen einer großen Datenbank nach relevanten Bildern basierend auf einem vorgegebenen Suchschlüssel. Auch bekannt als Content-Based Image Retrieval (CBIR) oder Content-Based Visual Information Retrieval (CBVIR), basiert diese Aufgabe traditionell auf Tag-Matching-Algorithmen. Allerdings bieten multimodale Deep-Learning-Modelle fortschrittlichere Lösungen und verringern die Notwendigkeit manueller Tagging-Prozesse.
Die Bildwiederherstellung kann auch auf die Videoabfrage ausgeweitet werden. Der Abfrageschlüssel kann eine Textunterschrift, ein Audio oder sogar ein anderes Bild sein, wobei Textbeschreibungen am häufigsten verwendet werden.
Verschiedene Aufgaben der cross-modalen Bildwiederherstellung umfassen:
Text-zu-Bild-Wiederherstellung: Finden von Bildern, die einer Textbeschreibung entsprechen.
Text- und Bildkomposition: Modifikation eines Abfragebildes basierend auf einer Textbeschreibung.
Cross-View-Bildwiederherstellung: Abruf von Bildern aus unterschiedlichen Perspektiven oder Blickwinkeln.
Skizze-zu-Bild-Wiederherstellung: Finden von Bildern, die einer handgezeichneten Bleistiftskizze entsprechen.
Ein praktisches Beispiel für die Bildwiederherstellung ist die Nutzung der „Bilder“-Sektion einer Suchmaschine, um eine Reihe von Bildern zu betrachten, die mit Ihrer Suchanfrage in Verbindung stehen.

Beispiel einer Bildsuche mit Text- und Bildabfrage
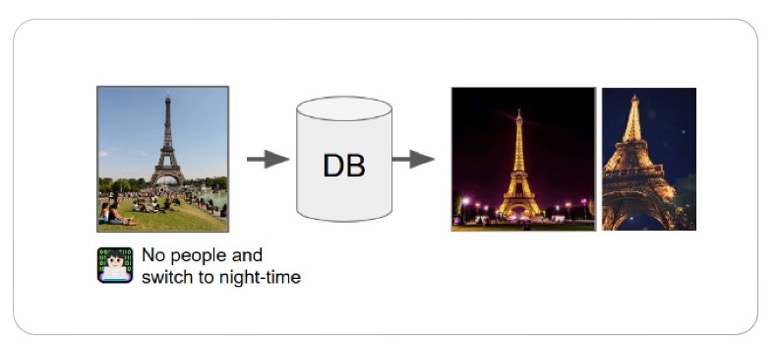
Quelle: Zusammenstellung von Text und Bild für Image Retrieval
Text-zu-Bild-Generierung
Die Text-zu-Bild-Generierung ist eine herausragende Anwendung des multimodalen Lernens, die sich auf die Übersetzung von Textbeschreibungen in visuelle Inhalte konzentriert. Bedeutende Modelle in diesem Bereich sind unter anderem OpenAIs DALL-E und Googles Imagen, die für ihre Fähigkeiten viel Aufmerksamkeit erregt haben.
Im Gegensatz zur Bildbeschreibung, bei der Text aus Bildern generiert wird, erstellt die Text-zu-Bild-Generierung neue Bilder basierend auf textuellen Eingaben. Bei einer kurzen Beschreibung erzeugen diese Modelle Bilder, die das Wesentliche und die Details des beschriebenen Textes einfangen. Kürzlich sind auch Text-zu-Video-Modelle entstanden, die diese Fähigkeit auf dynamische visuelle Inhalte ausweiten.
Diese Technologien sind in Bereichen wie der Fotobearbeitung, dem Grafikdesign und der digitalen Kunst wertvoll, da sie bei der Erstellung visueller Inhalte unterstützen und neue künstlerische Ideen inspirieren.

Text-zu-Bild-Generierung

Quelle: Imagen
Multimodale Deep-Learning-Datensätze
Multimodale Deep-Learning-Datensätze sind entscheidend für das Training von Modellen, die Informationen aus verschiedenen Datenquellen wie Text, Bildern, Audio und Video verarbeiten und integrieren können. Diese Datensätze ermöglichen es KI-Systemen, komplexe Beziehungen zwischen verschiedenen Modalitäten zu erlernen und ihre Leistung bei Aufgaben zu verbessern, die ein umfassendes Verständnis diverser Daten erfordern.
- Bestandteile multimodaler Datensätze
a. Textdaten:
- Quellen: Umfassen Dokumente, Social-Media-Beiträge, Nachrichtenartikel und mehr.
- Formate: Rohtext, tokenisierter Text, Einbettungen.
- Beispiele: Textbeschreibungen zu Bildern, Transkripte von Audio- oder Videoinhalten.
b. Bilddaten:
- Quellen: Fotografien, medizinische Bilder, Satellitenbilder und Kunstwerke.
- Formate: Pixelwerte, vorverarbeitete Merkmalsvektoren.
- Beispiele: Bilder mit beschreibenden Untertiteln oder Labels.
c. Audiodaten:
- Quellen: Sprachaufnahmen, Umgebungsgeräusche, Musik.
- Formate: Wellenformen, Spektrogramme, Audioeinbettungen.
- Beispiele: Audioclips mit entsprechenden Transkripten oder emotionalen Labels.
d. Videodaten:
- Quellen: Aufgezeichnete Videoclips aus verschiedenen Bereichen.
- Formate: Bildfolgen, zeitliche Merkmalsvektoren.
- Beispiele: Videos mit annotierten Szenen, Aktionen oder Dialogen.
2. Wichtige Datensätze im Multimodalen Lernen
a. MS COCO (Microsoft Common Objects in Context):
Beschreibung: Enthält Bilder mit detaillierten Objektannotationen und Bildunterschriften, verwendet für Aufgaben wie Bildbeschreibung und Objekterkennung.
Modalitäten: Bilder und Text.
b. Flickr30k:
Beschreibung: Beinhaltet Bilder, die mit mehreren beschreibenden Sätzen gekoppelt sind, und erleichtert Aufgaben wie Bild-zu-Text- und Text-zu-Bild-Generierung.
Modalitäten: Bilder und Text.
c. VGGSound:
- Beschreibung: Bietet audio-visuelle Daten mit beschrifteten Geräuschereignissen in Videos, nützlich für audio-visuelles Verständnis und Aktionserkennung.
- Modalitäten: Video und Audio.
d. AVA (Audio-Visual Scene-Aware Dialog):
- Beschreibung: Kombiniert Audio- und Bilddaten mit Dialogen und ermöglicht multimodale Aufgaben wie Videobeschreibung und Szenenverständnis.
- Modalitäten: Video, Audio und Text.
e. LSMDC (Large Scale Movie Description Challenge):
- Beschreibung: Besteht aus Filmclips mit detaillierten Beschreibungen und ist nützlich für Aufgaben wie Video-zu-Text- und Text-zu-Video-Generierung.
- Modalitäten: Video und Text.
3. Herausforderungen bei multimodalen Datensätzen
a. Datenabgleich: Sicherstellung, dass verschiedene Modalitäten genau miteinander gekoppelt sind, wie z. B. das Zuordnen von Bildern zu den entsprechenden Textbeschreibungen.
b. Datenqualität: Aufrechterhaltung einer hohen Qualität über alle Modalitäten hinweg, um ein effektives Training und eine zuverlässige Modellleistung zu gewährleisten.
c. Skalierbarkeit: Umgang mit großen Datenmengen aus verschiedenen Quellen unter Wahrung von Konsistenz und Kohärenz.
d. Annotationsaufwand: Der Bedarf an umfangreichen und genauen Annotationsdaten über mehrere Modalitäten hinweg, was ressourcenintensiv sein kann.
