Herausforderung
Das Unternehmen hatte kürzlich einen Online-Shop gestartet. Das Website-Team verbrachte viel Zeit damit, die Fragen der Käufer zu beantworten und Bewertungen und Kommentare zu moderieren. Es überrascht nicht, dass einige Leute die Regeln und die allgemeine Ethik der Website ignorierten und in ihren Beiträgen abfällige Sprache und Beleidigungen verwendeten.
Wie löst man so ein Problem am besten? Automatisierung. Das Unternehmen wollte künstliche Intelligenz (KI) nutzen, um einen Hassreden-Tracker und einen FAQ Chatbot zu erstellen. Also suchte man nach einer KI Software, der das konnte und stieß auf Elinext. Wir wurden für die Stelle ausgewählt, weil wir über die erforderlichen Fähigkeiten und Ressourcen verfügten.
Lösung
Elinext baute ein kleines agiles Team auf und tauchte direkt ein. Zunächst haben wir uns die fortschrittlichste Technologie zur Verarbeitung natürlicher Sprache (NLP) angesehen, die derzeit verfügbar ist. Unsere Ergebnisse legten nahe, dass wir das Design und die Entwicklung des FAQ Chatbots und des Hassreden-Detektors als zwei parallele Projekte für maschinelles Lernen (ML) behandeln sollten.
Hate Speech Detektor
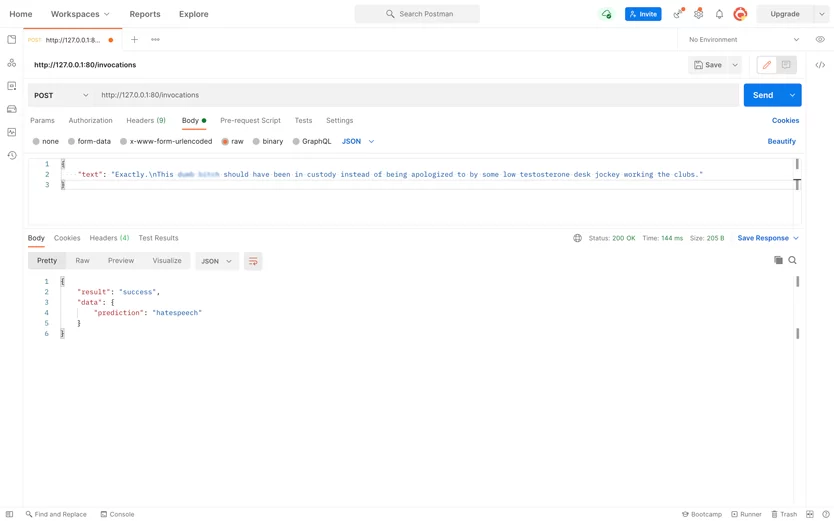
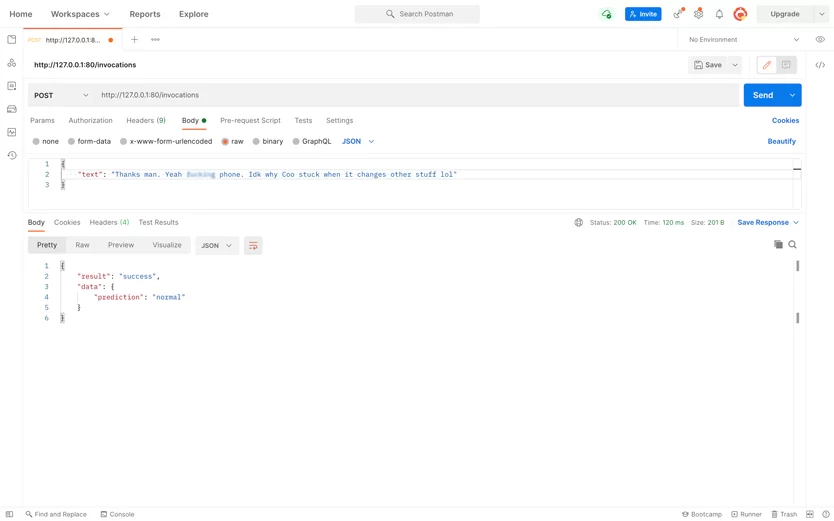
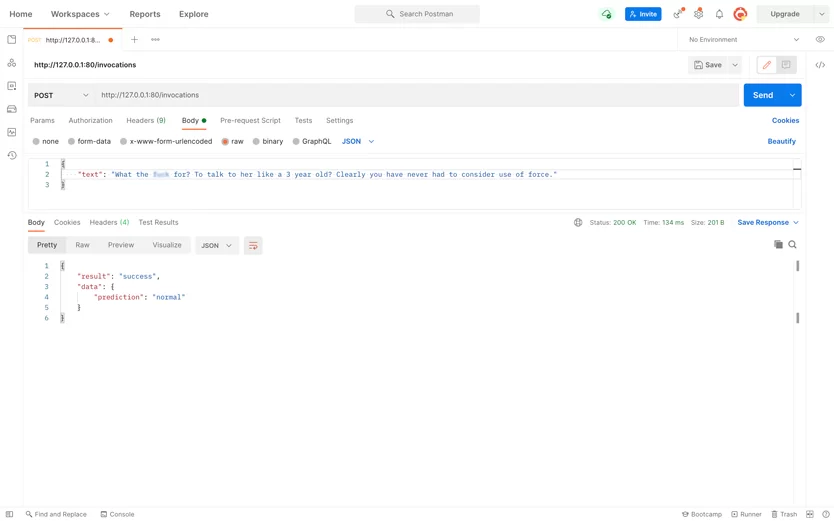
Wir mussten ein ML-Modell erstellen, das unangemessenen nutzergenerierten Text identifiziert. Das Modell erforderte einen Datensatz, eine Auswahl von Stoppwörtern und Phrasen, auf die trainiert werden musste. Und das hatte unser Kunde als neues Unternehmen nicht.
Die beste Lösung war, einen öffentlich zugänglichen Datensatz zu Hasssprache zu finden. Nachdem wir mehrere Optionen in Betracht gezogen hatten, entschieden wir uns für HateXplain.
Wir haben ein GitHub-Repository erstellt und den Datensatz dort neben einer Open-Source-KI abgelegt: Generative Pre-trained Transformer 2 (GPT-2). Dann automatisierten wir das KI-Training für den Datensatz mit Amazon Elastic Compute Cloud (Amazon EC2), das auf einer Nvidia-GPU ausgeführt wird.
Der Code des Perspektiven-Webdienstes wurde zum letzten Element des Repositorys. Nach dem Hochladen stellte die Anwendung den Dienst automatisch als Docker-Container zusammen mit den Binärdateien des Modells bereit. Letzteres ermöglicht es dem Kunden, die Anwendung in Zukunft zu analysieren und zu debuggen.
Der Prozess wird gestartet, indem der HTTP-Server gestartet wird, der das GPT-2-Modell und den Modell-Tokenizer hostet. Sobald der Server einen von einem Benutzer übermittelten Text erhält, teilt der Tokenizer den Text in semantische Einheiten auf, die von GPT-2 verarbeitet werden.
Dann werden die semantischen Einheiten durch die Softmax-Funktion geleitet. Die Funktion klassifiziert sie und das System markiert den eingegebenen Text als normal, hasserfüllt oder anstößig für den Website-Administrator.
Wir haben den Prozess von A bis Z automatisiert, indem wir virtuelle Server in GitHub Actions verwendet haben und sowohl unsere als auch die des Kunden eingespart haben
Interessanterweise kann die KI zwischen hasserfüllten news und solchen unterscheiden, die nur Kraftausdrücke verwenden. Es kann auch aggressive Rhetorik von Slangwörtern unterscheiden. Die Gesamtgenauigkeit des Modells liegt bei etwa 68 %, was bedeutet, dass es die Moderationszeit verkürzen kann.
FAQ Chatbot
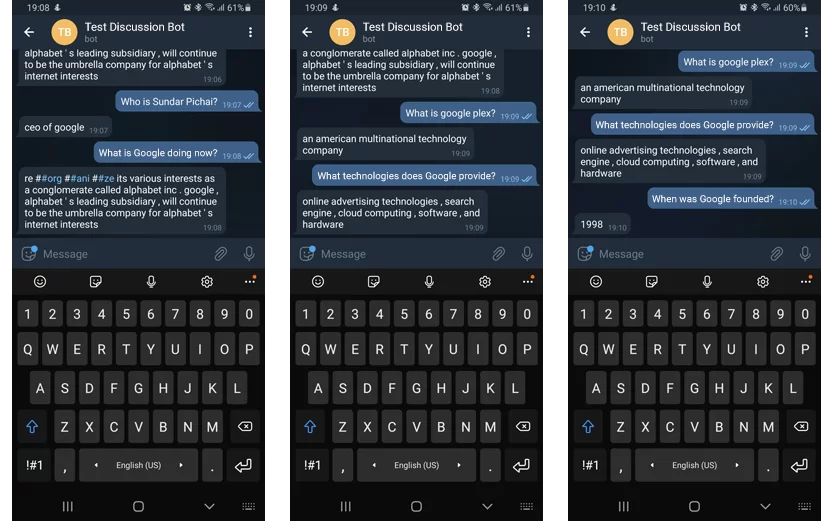
Der FAQ-Bot wurde benötigt, um eCommerce-bezogene Benutzerfragen zu beantworten. Das bedeutet, dass wir eine Wissensdatenbank aufbauen mussten, die es dem Bot ermöglicht, Benutzeranfragen zu verstehen und in der Datenbank nach Informationen zu suchen.
Wir haben dafür gesorgt, dass der Bot Abfragen mithilfe eines vortrainierten englischen Spracherkennungsmodells versteht: Bidirectional Encoder Representations from Transformers (BERT).
Aber bevor der Text erkannt wird, muss er in das System gelangen. Wie kommt es dazu?
Wir haben die HTTP-API und die Telegramm-API konfiguriert und zwei Optionen aktiviert. Zunächst öffnet der Website-Besucher ein Chat-Fenster, um mit dem Bot zu chatten. Der Bot schlägt ihnen außerdem vor, zu Telegram zu wechseln, und sendet ihnen einen Link zum Chat.
Der Webserver verarbeitet die Anfrage und schlägt Informationen in dem von einem Website-Administrator vorbereiteten Kontext nach. Administratoren können den Kontext ändern, anreichern und ersetzen.
Natürlich machen Menschen manchmal Tipp- oder Rechtschreibfehler. Aber unser Bot wird die Abfrage trotzdem richtig interpretieren (es sei denn, es handelt sich um ein unverdauliches Durcheinander von Buchstaben) und eine Antwort geben. Daher fühlt sich der Vorgang ähnlich an wie ein Chat mit einem geschulten Bediener.
Ergebnis
In zwei Wochen haben wir eine Anwendung erstellt, die dem Kunden Hunderte von Arbeitsstunden für Website-Administratoren gespart hat.
Darüber hinaus müssen sich Käufer nicht durch lange FAQs quälen, die in mehrere Abschnitte unterteilt sind. Stattdessen können sie den Chatbot fragen, was sie interessiert, und erhalten sofort eine Antwort.
Die beiden von uns erstellten Anwendungen haben dem Kunden Zeit und Geld gespart und den Kaufprozess optimiert.