Kunde
Das ist eine nicht-kommerzielle Präsentation, die speziell dazu erstellt wurde, unsere Expertise im Bereich maschinelles Lernen und die Lösung komplexer Softwareentwicklungsprobleme zu demonstrieren.
Herausforderungen
Händler haben oft Schwierigkeiten, ihre Lagerbestände zu optimieren. Wenn man zu viel von einem Produkt hortet, bleibt kein Platz für die Lagerung eines anderen. Kauft man zu wenig, riskiert man, dass die Kunden zu den Konkurrenten gehen.
Wir haben festgestellt, dass der Markt zunehmend versucht, dieses Problem mithilfe von vorausschauender Analytik zu lösen, und waren neugierig, ob wir eine solche Lösung anbieten könnten. Doch vorausschauende Analytik erforderte in diesem Fall separate Verkaufsdaten für verschiedene Waren, etwas, das man nicht leicht in Open-Source-Tools finden kann.
"Die Prognose der Nachfrage im Einzelhandel erfordert Verkaufsdaten pro Produkt, etwas, das man nicht leicht in frei verfügbaren Quellen finden kann."
Elinext hatte keine Erfahrung in der vorausschauenden Analytik im Einzelhandel. Daher haben wir uns daran gemacht, einen Fall zu modellieren, um die Besonderheiten des Sektors zu erlernen.
Prozess
Unser Team bestand aus zwei Maschinenlerningenieuren. Wir hatten Erfahrung mit KI und Projekten, bei denen wesentliche Daten nicht leicht verfügbar waren, aber wir hatten zuvor noch nie speziell für den Einzelhandel ML-Modelle entwickelt.
Das Team stand also vor zwei großen Herausforderungen: dem Mangel an Daten und dem Fehlen spezifischer Erfahrung. Hier ist, wie wir diese Herausforderungen angegangen sind.
Beschaffung der Daten
Wir begannen, das Datenproblem mit Recherche zu lösen. Einzelhändler würden ihre wertvollen Informationen nicht freiwillig mit uns teilen, und die Studien, die wir fanden, lieferten keine spezifischen Erkenntnisse. Aber bald wurde uns klar, dass es einen Ort geben könnte, an dem nützliche Zahlen zu finden sind: Berichte von Programmierwettbewerben.
Unsere Suche führte uns zur M5 Forecasting Accuracy 2020, einem der Makridakis-Wettbewerbe. Dieser seit 1982 bekannte Wettbewerb wird von der Universität von Nicosia und Kaggle ausgerichtet, einer Online-Community von Datenwissenschaftlern und ML-Experten.
"Wir fanden nützliche Einzelhandelsdaten von Walmart im Rahmen des M5 Forecasting Accuracy-Wettbewerbs."
Der ursprüngliche M5 Accuracy-Wettbewerb hatte 5.500 Teilnehmer, die Daten für mehr als 30.000 Waren von Walmart studierten. Die Tatsache, dass ein großer Einzelhändler so umfassende Daten für Experimente mit KI bereitstellte, machte sie zu einer einzigartigen Wissensquelle.
Und das war es, was es für uns zur perfekten Fallstudie machte, von der wir lernen konnten.
Auswahl des Entwicklungs-Frameworks
Elinext hatte keine vorherige Erfahrung im Aufbau von vorausschauender Analytik für den Einzelhandel. Daher begannen wir damit, die Ansätze zu analysieren, die sich im Wettbewerb als besonders erfolgreich erwiesen hatten. Das ist ein sicherer Weg, um zu vermeiden, die Fehler der Vorgänger zu wiederholen und die Entwicklungszeit im Vergleich zur Arbeit von Grund auf zu verkürzen.
Wir fanden Bewertungen einiger dieser Ansätze, was ein guter Anfang war. Leider fehlten den Bewertungen viele wesentliche Details. Nur wenige Beschreibungen wurden mit dem Code geliefert, und diese enthielten nicht die besten Wettbewerbsleistungen.
"Wir begannen damit, die Ansätze zu analysieren, die sich als besonders erfolgreich erwiesen hatten."
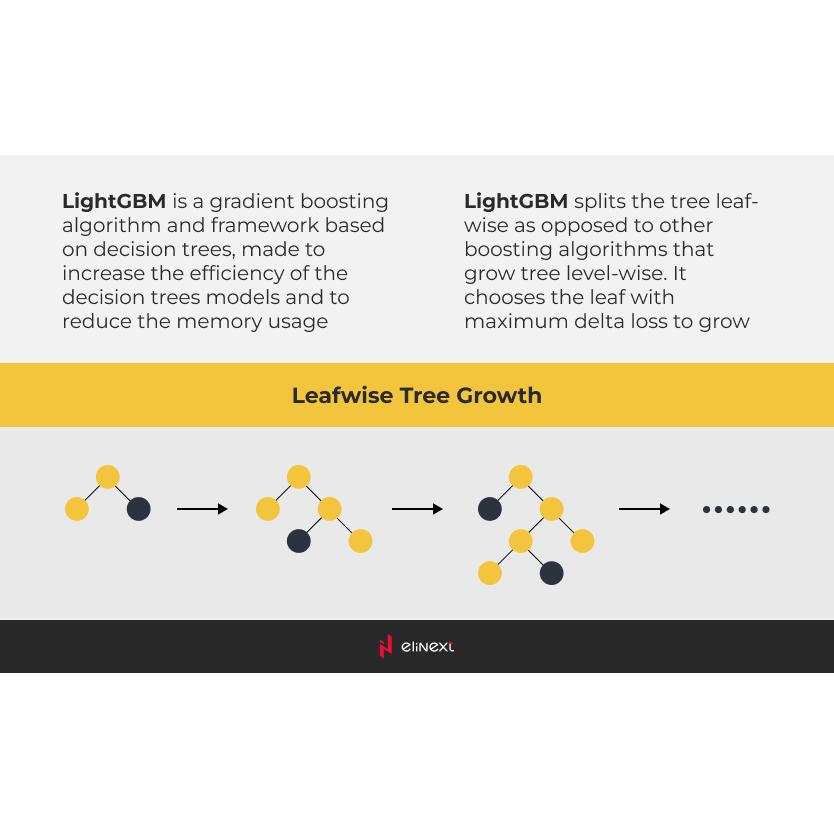
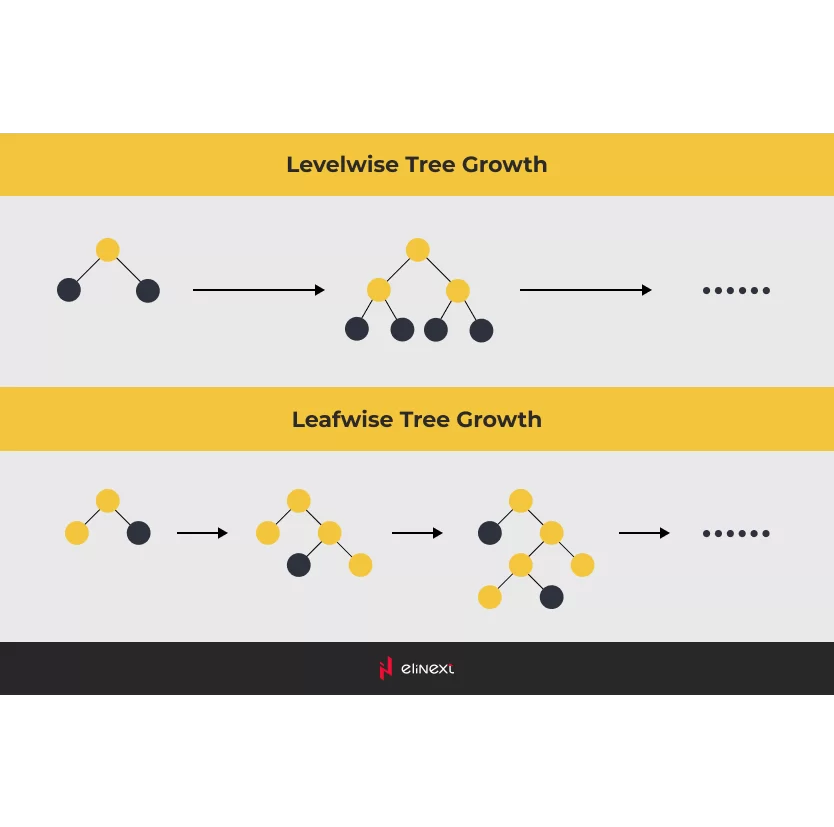
Dennoch vertieften wir uns in die siegreichen Ansätze und machten eine wichtige Entdeckung: Entscheidungsbäume übertrafen neuronale Netzwerke. Um genauer zu sein, verwiesen die Gewinner auf Gradient Boosting Machines (GBMs). Unter diesen hatte sich LightGBM als das beste Framework erwiesen, um ein ML-Modell für die Aufgabe zu entwickeln.
Produkt
Festlegen des Schulungsdatensatzes
Die Daten, die wir im Wettbewerb gefunden haben, stellten an sich bereits eine Herausforderung dar.
Zunächst einmal waren etwa 60% der Datensätze Nullen. Das machte es schwierig, die Daten mit standardmäßigen analytischen Methoden zur Erfassung von Abhängigkeiten zu verwenden. Daten wie diese wurden ausgewählt, um die Teilnehmer dazu zu bringen, über praktische Anwendungen hinauszugehen und zur Entwicklung theoretischer Methoden beizutragen.
Datensätze mit so vielen Lücken beeinflussen die potenzielle Vorhersagegenauigkeit. Wir wussten nicht, ob diese Nullen auf eine geringe Nachfrage oder Lücken in der Versorgung zurückzuführen waren. Und es blieb jedem überlassen zu erraten, wie sich diese Nullen zu den Nachfragebeobachtungen an anderen Tagen verhielten.
Die durch den Wettbewerb bewährten Ansätze können jedoch erstaunliche Ergebnisse liefern, wenn sie auf umfassendere, vollständige Datensätze angewendet werden.
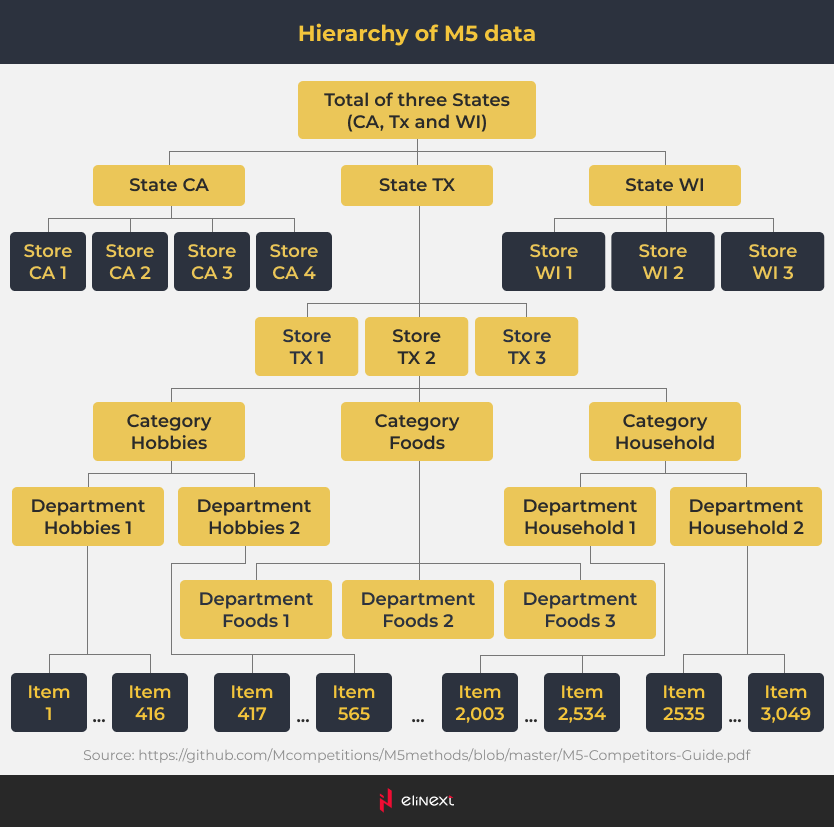
Zweitens war der gegebene Datensatz riesig und über mehrere Aggregationsebenen verteilt.
Wir fanden Verkaufsdaten für insgesamt 3049 Waren in 10 Geschäften in 3 Bundesstaaten (Kalifornien, Texas und Wisconsin) für 28 Tage. Die Daten wurden auch nach Kategorie (Lebensmittel, Haushalt und Hobbys) und Abteilung (z.B. Lebensmittel 1, Lebensmittel 2) gruppiert. Darüber hinaus wurden Faktoren wie Werbung und Promotion-Aktivitäten, Ereignisse wie Feiertage, Wochentage und mehr berücksichtigt.
Infolgedessen umfasste der Datensatz 42.840 Zeitreihen. Das brachte ihn nahe an reale Situationen, in denen Einzelhändler Tausende von Produkten führen. Indem sie eine große Anzahl von Zeitreihen gleichzeitig und innerhalb eines vernünftigen Zeitrahmens modellierten, schufen die Teilnehmer einen praktischen, nützlichen Ansatz.
"Der Datensatz umfasste 42.840 Zeitreihen für 3049 Waren aus 10 Geschäften in 3 Bundesstaaten über einen Zeitraum von 28 Tagen."
Aufbau des Machine Learning-Modells
Wir folgten dem Ansatz, der auf LightGBM basiert, und verwendeten unsere eigene Modellkonfiguration und Satz von Merkmalen. Diese Merkmale umfassten fast 30 Faktoren wie zeitlich verzögerte Verkaufswerte, saisonale Effekte, Preis und mehr. Viele von ihnen wurden von den Teilnehmern des Wettbewerbs verwendet, wie es die Natur des Projekts nahelegte.
Wir stellten fest, dass zeitlich verzögerte Verkaufswerte und Produkt-IDs den größten Einfluss auf die Ergebnisse in unserem Modell hatten. Jede Produkt-ID bezog sich auf eine bestimmte Serie, was das Modell ermöglichte, spezifische Verkaufsdynamiken für jedes Produkt zu berechnen.
Um ein Modell zu erstellen, das im realen Leben anwendbar ist, versuchten wir zu berechnen, welche Genauigkeit tatsächlich mit dem verfügbaren Datensatz erreicht werden konnte. Hier ist, was wir getan haben.
Wir wählten etwa 20 Zeitreihen fast ohne Nullen aus. Diese Produkte gehörten zur Kategorie Lebensmittel. So umgingen wir die Hauptkomplexität des Hauptdatensatzes (Nullen) und können auch vernünftigerweise annehmen, dass die Serien vorhersehbarere Muster als andere Warenkategorien aufweisen. Die Verkaufszyklen von Lebensmitteln sind kürzer, ihre Reaktionen auf Kalendereffekte sind offensichtlicher usw. Daher glauben wir, dass die Vorhersagekraft eines beliebigen Modellierungsansatzes auf diesem Datensubset höher sein sollte als auf dem gesamten Datensatz. Diese Daten sind unser Maßstab für den gesamten Datensatz.
Wir haben dieses Datensubset mit einem sehr konventionellen statistischen Ansatz, ARIMA, modelliert. LightGBM ist viel effizienter, zumindest in Bezug auf die Verarbeitungszeit, wenn es um große Datensätze geht. Für einen kleinen Datensatz reichte jedoch ARIMA aus, um schnell die Wahrheit aufzudecken. Für die meisten Serien haben wir Modelle erstellt, die alle Konventionen der Zeitreihenanalyse erfüllten, einschließlich Fehlerterme mit weißem Rauschen. Das gesamte Muster hängt also von der Dynamik der Variablen ab, in unserem Fall den täglichen Verkäufen, die dann vom Modell abgedeckt werden. Das weiße Rauschen ist ein rein unvorhersehbarer Prozess. Wir können es nicht modellieren. Wir kommen zu dem Schluss, dass eine von einem Modell abgedeckte Serie mit keiner Alternative besser modelliert werden kann. Wir können diese Serien als unseren Maßstab für unseren Datensatz verwenden. Bei diesen Serien lag die beste Vorhersagegenauigkeit in absoluten Zahlen nicht wesentlich über 70%. Für den gesamten Datensatz (hier können wir nur annehmen), wird sie wahrscheinlich mit keinem Ansatz deutlich höher liegen.
Wir können von den M5-Wettbewerbsdaten keine beeindruckende, absolute Genauigkeit erwarten, obwohl die Situation für andere Einzelhandelsdatensätze unterschiedlich sein kann. Der Modellierungsprozess ist datenabhängig. Er sollte die Geschäftsdatenerzeugungsprozesse hinter einem tatsächlichen Datensatz aufdecken.
Aber für diesen bestimmten Datensatz können wir unsere Modellierungsfähigkeiten in relativen Begriffen messen, indem wir sie mit den Ergebnissen der Führenden vergleichen.
Ergebnisse
Die Wettbewerbsveranstalter bewerteten die Teilnehmer anhand der gewichteten Wurzel des mittleren quadratischen skalierten Fehlers (WRMSSE). Je niedriger die Rate, desto besser hat der Entwickler abgeschnitten. Wir erzielten einen Wert von 0,54, was uns unter den besten zehn von 5.500 Teilnehmern platzierte.
Aber der von uns entwickelte Algorithmus kann über die Nachfrageprognose hinaus eingesetzt werden. Er kann Wechselwirkungen zwischen mehreren Faktoren aufdecken, die für das ungeübte Auge unsichtbar sind. Einzelhändler können diese Wechselwirkungen nutzen, um ihre Budgets besser zu planen und sicherzustellen, dass die Waren früher als später in den Warenkörben der Kunden landen.
"Elinext erreichte eine Vorhersagegenauigkeit unter den besten zehn von 5.500 Teilnehmern."